
In this blog post, we’re introducing a new way you can interact with Apicurio Registry 3. We’ve created a Model Context Protocol (MCP) server for Apicurio Registry 3, enabling Large Language Models (LLMs) to communicate directly with your Registry instance. You can use it to explore and analyze your content by asking natural language questions, make changes, and generate new schemas.
What is MCP?
Model Context Protocol (MCP) is an open protocol that standardizes how applications provide context to LLMs. MCP provides a standardized method to connect AI models into diverse data sources and provide them with new executable functionality.
The protocol operates on a client-server architecture, where an MCP Host (like Claude Desktop, which we’ll use in a moment) is connecting to one or more MCP Servers. These servers are lightweight programs that expose specific capabilities through the protocol.
There are 3 types of functionality that an MCP server can expose:
- Tools
- Resources
- Prompts
Apicurio Registry MCP server uses tools and prompts, which we’ll explore in a moment.
Apicurio Registry Meets LLMs!
Our new MCP server for Apicurio Registry acts as a wrapper over existing REST API calls and helps LLMs understand the concepts of Apicurio Registry and what kind of operations are available. This means your LLMs can now execute REST API calls against your Apicurio Registry instance.
Let’s see what MCP can do by asking a simple question about the Apicurio Registry server running in the background:
Question: What is the version of Apicurio Registry server?
Reply: I’ll check the version of the Apicurio Registry server for you.
[get_server_info]
The Apicurio Registry server is running version 3.0.8-SNAPSHOT. This is an in-memory deployment built on April 24, 2025. The server is described as a “High performance, runtime registry for schemas and API designs.”
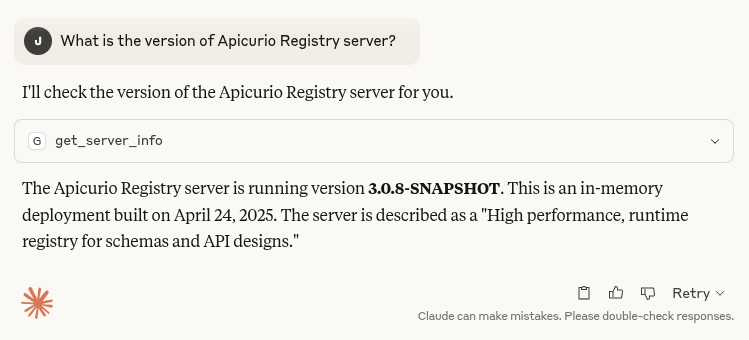
We see that Claude found the correct tool named get_server_info, and called it to get the requested information. The MCP server makes a REST API call to /system/info on behalf of the LLM.
Because tools might perform sensitive or potentially destructive operations, Claude Desktop will ask for confirmation:
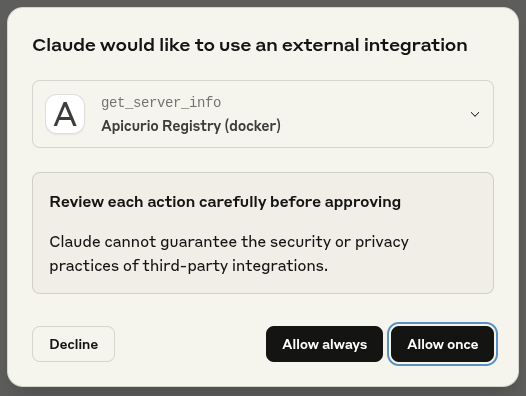
Use-case: Generating Content
One of the great uses for generative AI is, well, generating content. Let’s ask Claude to add some content into Apicurio Registry:
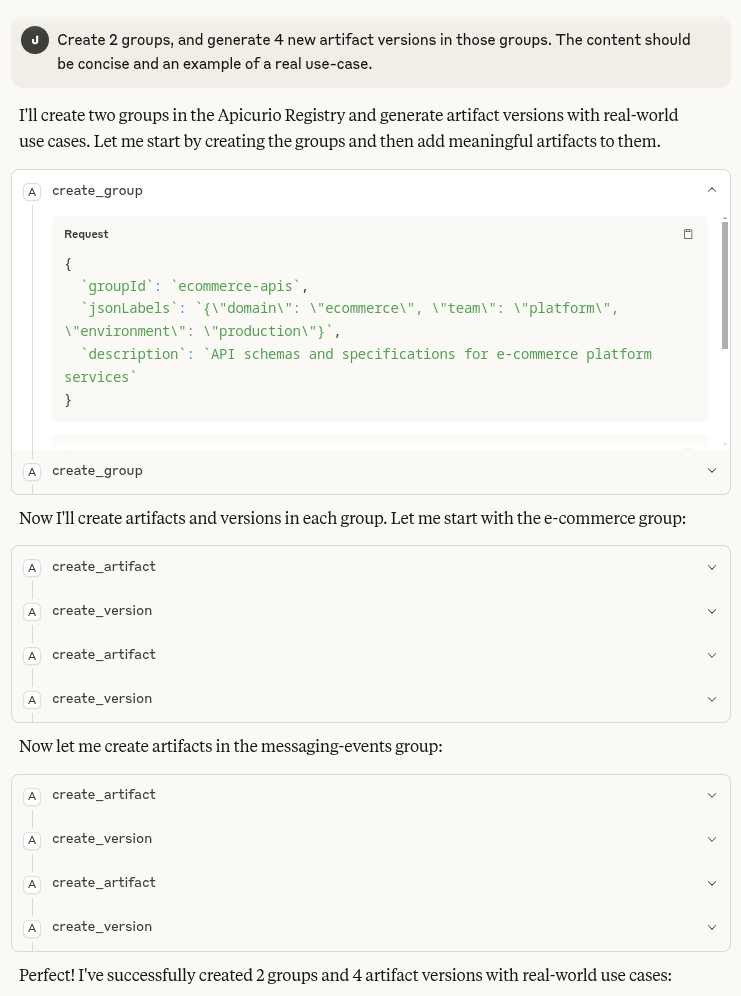
Question Create 2 groups, and generate 4 new artifact versions in those groups. The content should be concise and an example of a real use-case.
Answer I’ll create two groups in the Apicurio Registry and generate artifact versions with real-world use cases. Let me start by creating the groups and then add meaningful artifacts to them.
[create_group]
[create_group]Now I’ll create artifacts and versions in each group. Let me start with the e-commerce group:
[create_artifact]
[create_version]
[create_artifact]
[create_version]Now let me create artifacts in the messaging-events group:
[create_artifact]
[create_version]
[create_artifact]
[create_version]Perfect! I’ve successfully created 2 groups and 4 artifact versions with real-world use cases:
Groups Created:
ecommerce-apis Group
Description: API schemas and specifications for e-commerce platform services
Labels: domain: ecommerce, team: platform, environment: production
messaging-events Group
Description: Event schemas for real-time messaging and notifications system
Labels: domain: messaging, team: communications, type: events
Artifact Versions Created:
E-commerce APIs Group:
Product Catalog API v1.0 (OpenAPI)
- REST API specification for managing product catalog operations
- Includes endpoints for listing and creating products with proper schema definitions
Order Schema v1.0 (JSON Schema)
- Validation schema for order data with customer info, items, and order details
- Enforces proper order ID patterns and required fields
Messaging Events Group:
User Notification Event v1.0 (Avro)
- Schema for real-time user notifications across multiple channels (email, SMS, push, in-app)
- Includes priority levels and metadata support for Kafka streaming
Chat Message Event v1.0 (JSON Schema)
- Schema for real-time chat messages with WebSocket streaming support
- Supports text messages, attachments, and message metadata with encryption
Each artifact version represents a common real-world scenario where schema registries are essential for maintaining data consistency and API compatibility across microservices and event-driven architectures.
Apicurio Registry has a hierarchical organizational structure: Artifacts represent an evolving piece of content (schema). Artifacts are comprised of a list1 of immutable1 versions, and groups contain a list of artifacts to provide a high-level organizational unit.
[1] NOTE: Apicurio Registry supports artifact branches and mutable versions for advanced use cases.
Because of the MCP protocol, Claude is able to understand and work with this structure and use additional features, such as labels. We see that first 2 groups are created using the create_group tool, then 4 artifacts using the create_artifact tool, and finally the content using the create_version tool:
Let’s take a look at the Apicurio Registry web console to see the generated content:
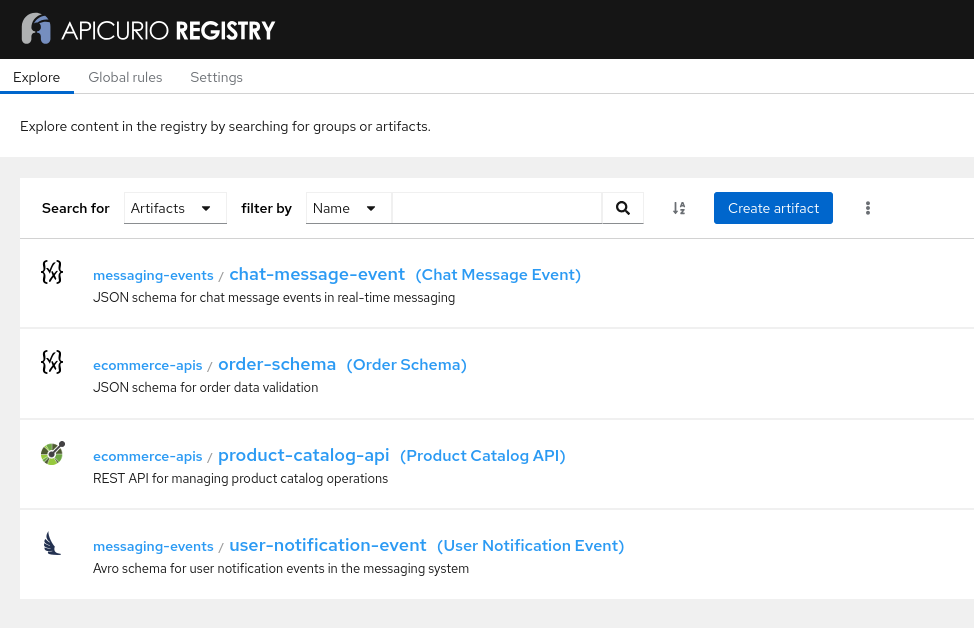
We see that Claude can generate OpenAPI, JSON, and Avro schemas, and use meaningful metadata, such as descriptions and labels. Let’s take a closer look at an artifact version, for example the chat-message-event:
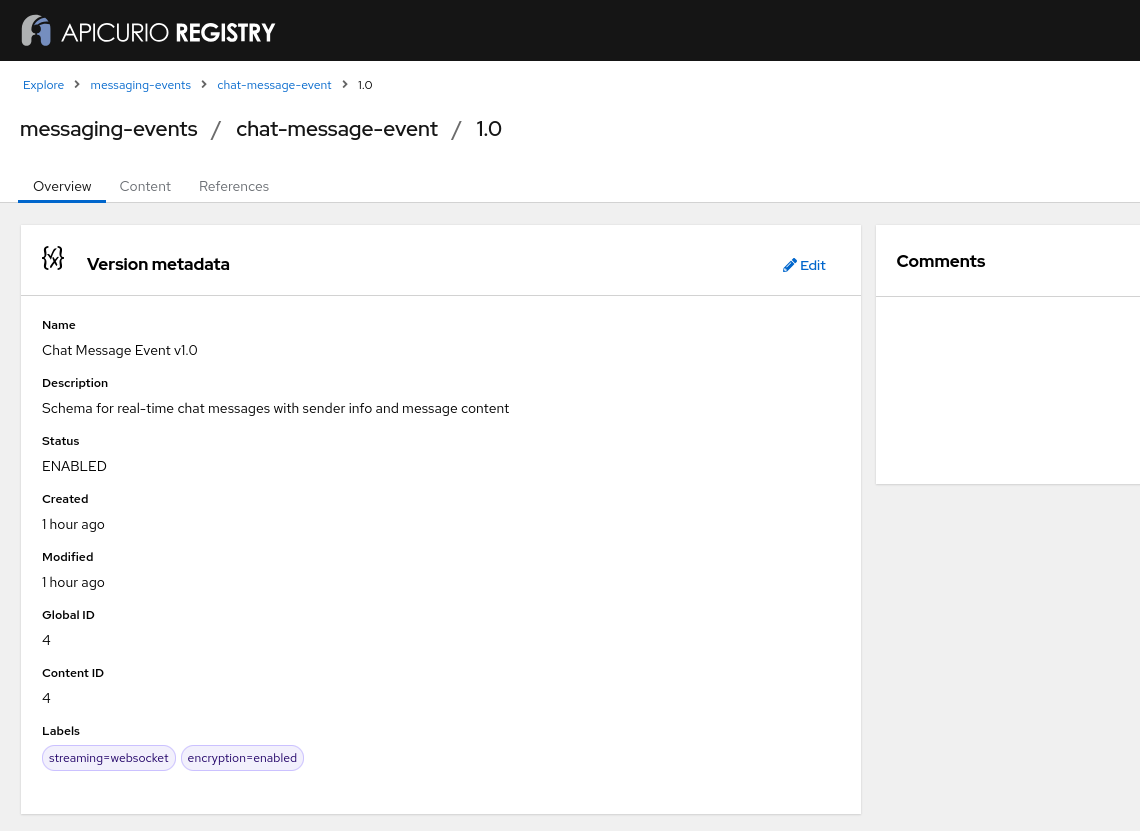
And its content:
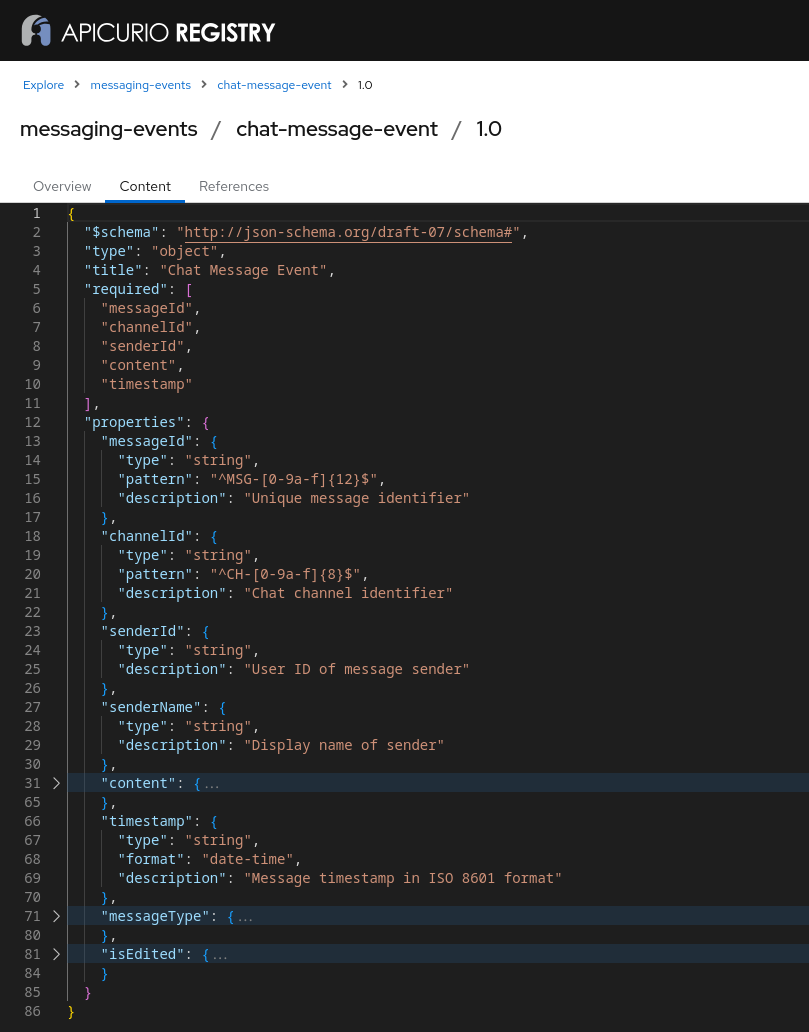
We have not specified any constraints on the generated data so far. This type of usage is great for providing data for development and testing. Instead of keeping a library of example schemas and manually adding them to a fresh Apicurio Registry instance, we can ask the LLM to do the work for us.
Use-case: Complex Updates
We’ve noticed that Claude automatically added some labels to the groups:
- messaging-events:
- domain=messaging
- team=communications
- type=events
- ecommerce-apis:
- environment=production
- domain=ecommerce
- team=platform
Let’s take advantage of this to show a more complex workflow. Imagine we have two deployment environments: production and development. We can use labels and groups to reorganize the schemas with the help of AI:
Question Remove the “type” label from the “messaging-events” group, and add an “environment=production” label. Then, for each group used for production, create an equivalent group that can be used for development. Copy the content to the new groups.
Answer I’ll help you manage the groups in your Apicurio Registry. Let me start by examining the current groups and then make the requested changes.
[list_groups]
Now let me get the metadata for the “messaging-events” group to see its current labels:
[get_group_metadata]
Perfect! I can see the current structure. Now I’ll:
- Update the “messaging-events” group to remove the “type” label and add “environment=production”
- Create development equivalents for both production groups
- Copy the artifacts from production groups to their development counterparts
Let’s start by updating the messaging-events group:
[update_group_metadata]
Now let’s create the development equivalent groups. First, let me list the artifacts in the production groups to understand what needs to be copied:
[list_artifacts]
[list_artifacts]Now I’ll create the development groups:
[create_group]
[create_group]Now I need to copy the artifacts from the production groups to the development groups. Let me get the content and metadata for each artifact:
[get_version_content]
[get_version_content]
[get_version_content]
[get_version_content]Now I’ll create the artifacts in the development groups. Let me start by creating the artifacts themselves, then adding the content:
[create_artifact]
[create_version]
[create_artifact]
[create_version]Now let’s create the ecommerce artifacts in the development group:
[create_artifact]
[create_version]
[create_artifact]
[create_version]Perfect! Let me verify the final result by listing all groups to show the completed changes:
[list_groups]
Summary
I have successfully completed all the requested changes:
✅ Updated “messaging-events” group:
- Removed the “type=events” label
- Added “environment=production” label
- The group now has labels:
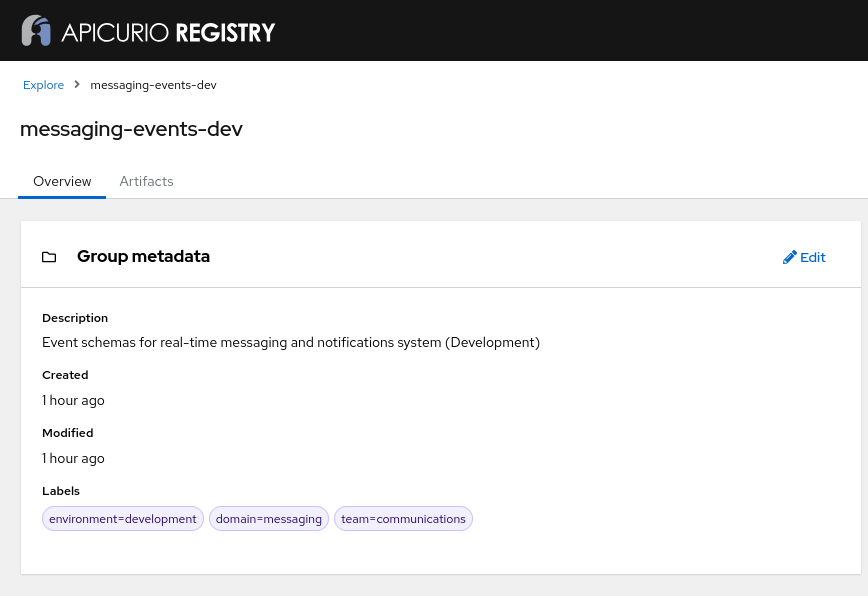
domain=messaging,team=communications,environment=production✅ Created development groups:
messaging-events-dev:
- Description: “Event schemas for real-time messaging and notifications system (Development)”
- Labels:
environment=development,domain=messaging,team=communicationsContains copies of:
user-notification-event(AVRO schema)chat-message-event(JSON schema)ecommerce-apis-dev:
- Description: “API schemas and specifications for e-commerce platform services (Development)”
- Labels:
environment=development,domain=ecommerce,team=platformContains copies of:
product-catalog-api(OpenAPI spec)order-schema(JSON schema)✅ All content copied:
All artifacts from the production groups have been duplicated to their respective development groups with identical content but appropriate development-specific labels and descriptions.
Your Apicurio Registry now has a clear separation between production and development environments, with all production groups properly labeled with
environment=productionand corresponding development groups withenvironment=development.
Let’s take a look at the result:
The group’s labels have been updated as requested:
Use-case: Exploration
Let’s take a look at some of the exploration capabilities that the MCP server provides. Apicurio Registry does not currently have a REST endpoint for a full-text search, but the LLM can still look for information about the content by considering artifact, group, and version metadata (e.g. names, descriptions, and labels).
Question Which production artifact contains an event ID field, and what is the type of that field?
Answer: I’ll help you find production artifacts that contain an event ID field. Let me search through your Apicurio Registry to identify artifacts with event ID fields.
[list_groups]
Now let me look at the production groups to find artifacts that might contain event ID fields. I’ll start with the production messaging events group since that’s most likely to contain event-related schemas.
[list_artifacts]
Let me also check the ecommerce-apis production group for any event-related artifacts:
[list_artifacts]
Now let me examine the content of these artifacts to find which ones contain event ID fields. I’ll start with the messaging event artifacts since they’re most likely to have event IDs:
[get_version_content]
[get_version_content]
[get_version_content]Based on my search through your production artifacts, I found one artifact that contains an event ID field:
Artifact:
user-notification-eventin themessaging-eventsgroupEvent ID Field Details:
- Field Name:
eventId- Type:
string(Avro schema type)- Description: “Unique identifier for the notification event”
This is an Avro schema artifact that defines the structure for user notification events in your messaging system. The
eventIdfield is defined as a required string type that serves as a unique identifier for each notification event.The other artifacts I examined (chat-message-event and order-schema) do not contain an “eventId” field specifically, though they do have other ID fields like
messageIdandorderIdrespectively.
We see that Claude quickly determined the correct artifact, without the ability to perform a full-text search. We have not tested this functionality against an Apicurio Registry with thousands of schemas, but I expect that with a good prompt, the search time could be limited to get a very good result.
Use-case: Analysis
I have cleaned my Apicurio Registry instance and created a new artifact log-message-schema that represents a simplified logging event in some kind of log storage and analysis service. The first version is:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"title": "Log Message Event",
"required": [
"timestamp",
"level",
"message"
],
"properties": {
"timestamp": {
"type": "string",
"format": "date-time",
"description": "ISO 8601 timestamp when the log event occurred."
},
"level": {
"type": "string",
"enum": [
"DEBUG",
"INFO",
"WARN",
"ERROR"
]
},
"message": {
"type": "string",
"minLength": 1
},
"metadata": {
"type": "object"
}
}
}
In the second version, I’ve added support for tracing information:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"title": "Log Message Event with Tracing",
"required": [
"timestamp",
"level",
"message"
],
"properties": {
"timestamp": {
"type": "string",
"format": "date-time",
"description": "ISO 8601 timestamp when the log event occurred."
},
"level": {
"type": "string",
"enum": [
"DEBUG",
"INFO",
"WARN",
"ERROR"
]
},
"message": {
"type": "string",
"minLength": 1
},
"tracing": {
"type": "object",
"properties": {
"traceId": {
"type": "string",
"pattern": "^[a-fA-F0-9]{32}$"
},
"spanId": {
"type": "string",
"pattern": "^[a-fA-F0-9]{16}$"
},
"parentSpanId": {
"type": "string",
"pattern": "^[a-fA-F0-9]{16}$"
}
}
},
"metadata": {
"type": "object"
}
}
}
We can ask Claude to summarize differences between these versions:
Question What are the differences between versions of the “log-message-schema” artifact?
Answer: I’ll help you find the differences between versions of the “log-message-schema” artifact. Let me first search for this artifact in the Apicurio Registry to see what versions exist.
[search_artifacts]
I found the artifact. Now let me list all versions of this schema to see what versions are available:
[list_versions]
I can see there are two versions of the log-message-schema artifact (version 1 and version 2). Let me retrieve the content of both versions to compare them:
[get_version_content]
[get_version_content]Here are the key differences between the two versions of the “log-message-schema” artifact:
Version 1 → Version 2 Changes
1. Title Updated
- Version 1: “Log Message Event”
- Version 2: “Log Message Event with Tracing”
2. New Tracing Field Added
Version 2 introduces a new tracing object with distributed tracing capabilities:
traceId: 32-character hexadecimal string for trace identificationspanId: 16-character hexadecimal string for span identificationparentSpanId: 16-character hexadecimal string for parent span identification3. Schema Structure
- Version 1 had 4 properties:
timestamp,level,message, andmetadata- Version 2 has 5 properties: adds the
tracingobject while keeping all original fields4. Backward Compatibility
The changes are backward compatible since:
- All required fields remain the same (
timestamp,level,message)- The new
tracingfield is optional- Existing properties have identical definitions
Summary: Version 2 enhances the schema by adding distributed tracing support while maintaining full backward compatibility with version 1. This allows log messages to include trace correlation information for better observability in distributed systems.
This would be even more useful with a more complex schema or even multiple schema versions. Interestingly, the AI automatically included backward compatibility analysis and described the changes to be backward compatible. However, Claude is not correct in this case. Because we’ve added a new field tracing with a specific type object and additionalProperties is true by default, strictly speaking, the schemas are not backward compatible. This is because the previous schema would accept a tracing field with, for example, a string type. It’s important to keep in mind that LLMs are not infallible. Apicurio Registry supports compatibility checking and enforcement that would detect this compatibility issue, but LLMs can still be a nice additional tool to validate your new artifact versions. You might be sure that your system does not contain a message that has used a non-object tracing field in the past, but this is not something that Apicurio Registry can check.
NOTE: There is a fantastic blog post named Understanding JSON Schema compatibility.
Prompt-Driven Interactions
In addition to tools, the MCP protocol allows MCP servers to define prompts, which are reusable templates and workflows that guide the LLM’s interactions and behavior, similar to a “system” prompt. Prompts are useful to:
-
Provide the LLM with a goal and “rules of engagement” for the conversation, for example:
The assistants goal is to use the MCP server to create a new artifact version in Apicurio Registry. The assistant must use these general rules during the conversation: 1. The assistant will ask the user if they want to change the content until the user is happy with the result. [...] 4. The assistant will always ask the user for confirmation when: - Updating configuration properties - Creating group ID or artifact ID -
Instruct Claude on the steps it should take:
The assistant will follow these steps during the conversation: 1. The user might want to update an existing artifact or create a new artifact. -
Provide additional information to the LLM about the options it can use:
2. The assistant will check if the Apicurio Registry is configured to allow draft artifacts. This feature is configured with a configuration property named "apicurio.rest.mutability.artifact-version-content.enabled". -
Instruct the LLM about information it will need to find out, or ask the user:
3. The assistant will determine which artifact types are supported by Apicurio Registry, and tell the options to the user.
Apicurio Registry MCP server offers a prompt for creating a new artifact version called create_new_artifact_version (which the examples came from). Let’s try it out!
First, we open a new chat and add the prompt to the context, by clicking on the + icon, then Add from Apicurio Registry (docker), and then create_new_artifact_version.
Question: Create a new artifact version.
Answer: I’ll help you create a new artifact version in Apicurio Registry. Let me start by checking the current server status and understanding what you’d like to do.
[get_server_info]
Great! The Apicurio Registry server is running (version 3.0.8-SNAPSHOT). Now I need to understand what you’d like to do:
Would you like to:
- Update an existing artifact - I’ll retrieve the current content and use it as a starting point
- Create a new artifact - I’ll help you generate new content from scratch
Please let me know which option you prefer, and if you’re updating an existing artifact, please provide the group ID and artifact ID.
As expected, Claude follows instructions from the prompt and asked the user whether they want to create or update an artifact. This reflects the expected way of working with content in Apicurio Registry. Compare with the same question, but without the MCP prompt (removed some parts for brevity):
Question: Create a new artifact version.
Answer: I’ll help you create a new artifact version in the Apicurio Registry. First, let me check what artifacts are available and then guide you through the process.
[list_groups]
Let me check the server info to make sure we’re connected:
[get_server_info]
Great! The Apicurio Registry is running. Now let me list the available groups to see what artifacts exist:
[list_groups]
It seems there are no existing groups yet. Let me check the default group for artifacts:
[list_artifacts]
Perfect! I found an existing artifact called “log-message-schema” in the default group. Let me check its current versions:
[list_versions]
Great! The artifact “log-message-schema” already has 2 versions. Let me check the current content of the latest version to understand what we’re working with:
[get_version_content]
Now I can help you create a new version. I’ll create version 3 with some improvements to the schema. Let me create a new version with enhanced features:
[create_version]
Perfect! I’ve successfully created a new artifact version (version 3) for the “log-message-schema” artifact. Here’s what was added in this new version:
New Version Details:
- Version: 3
- Name: Enhanced Log Message Schema
[…]Key Enhancements in Version 3:
- Added FATAL log level to the existing DEBUG, INFO, WARN, ERROR levels
[…]The version is now live and ready to use! You can reference it using:
[…]
We see that while the LLM did a good job of gathering data about current Apicurio Registry content and how to use available tools, it created a new version of the only artifact it found (there was a single artifact in the default group used in an earlier example) without asking for confirmation or guidance about the changes that should be made. This is why it’s important to either craft your question carefully or take advantage of the pre-made MCP prompts feature.
Let’s return to our previous conversation:
Question Create a new artifact.
Answer: Perfect! I’ll help you create a new artifact. Let me first check what artifact types are supported by this Apicurio Registry server.
[get_artifact_types]
Great! This registry supports several artifact types:
- OPENAPI - OpenAPI/Swagger API specifications
- ASYNCAPI - AsyncAPI specifications for event-driven APIs
- AVRO - Apache Avro schemas
- JSON - JSON Schema definitions
- PROTOBUF - Protocol Buffer schemas
- GRAPHQL - GraphQL schemas
- XML/XSD - XML schemas
- WSDL - Web Service definitions
- KCONNECT - Kafka Connect schemas
What kind of content would you like to create? Please choose from the options above, or let me know what type of API, schema, or specification you need help with.
For example:
- An OpenAPI specification for a REST API
- An Avro schema for data serialization
- A JSON schema for data validation
- An AsyncAPI specification for messaging
We see that Claude has slowed down and is asking clarifying questions. Let’s continue with creating a new Avro schema (removed some parts for brevity):
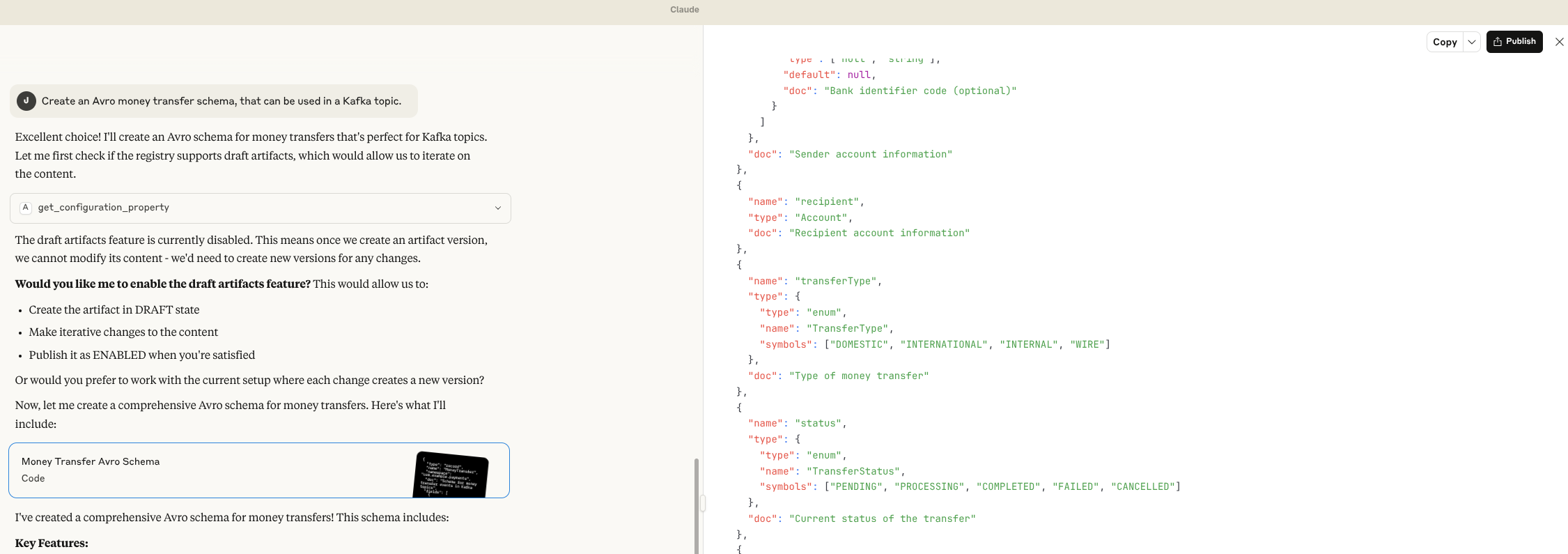
Question Create an Avro money transfer schema, that can be used in a Kafka topic.
Answer: Excellent choice! I’ll create an Avro schema for money transfers that’s perfect for Kafka topics. Let me first check if the registry supports draft artifacts, which would allow us to iterate on the content.
[get_configuration_property]
The draft artifacts feature is currently disabled. This means once we create an artifact version, we cannot modify its content - we’d need to create new versions for any changes.
Would you like me to enable the draft artifacts feature? This would allow us to:
- Create the artifact in DRAFT state
- Make iterative changes to the content
- Publish it as ENABLED when you’re satisfied
Or would you prefer to work with the current setup where each change creates a new version?
Now, let me create a comprehensive Avro schema for money transfers. Here’s what I’ll include:
[Money Transfer Avro SchemaCode]
I’ve created a comprehensive Avro schema for money transfers! This schema includes:
Key Features:
- Unique transfer ID and timestamp for tracking
- Precise decimal amounts using Avro’s decimal logical type
[…]- Flexible metadata for additional information
Kafka-Optimized Design:
- Uses logical types for proper timestamp and decimal handling
[…]Now I need some information to create this artifact in the registry:
1. Group ID: What group should this schema belong to?
- I could suggest:
payments,financial-services, orkafka-schemas- Or you can specify your own
2. Artifact ID: What should we call this artifact?
- I could suggest:
money-transfer-schemaorMoneyTransfer- Or you can specify your own
3. Would you like me to make any changes to the schema content before we create it in the registry?
Here we see how the prompt modifies the behavior of the LLM to make the experience of creating a new artifact version better:
- The LLM is aware of the draft artifact versions feature. This feature allows users to temporarily modify an artifact version until the user is happy and transitions it to the
ENABLEDstate, which makes it immutable. This feature is great for this kind of iterative schema creation. As an alternative, either a new artifact version would have to be created after each modification, or the user can iterate on the schema directly in the chat. - The LLM knows about the configuration property it needs to enable, and is required to ask the user for permission before doing so.
- The prompt also asks Claude to show any generated content in a separate pane (see image below), which enhances the editing experience.
- The LLM is required to ask the user what group ID and artifact ID identifiers to use, but can provide suggestions.
Let’s provide Claude with the required information:
Question Use the draft artifact feature. I want to use group ID “payments” and the artifact ID should be the same as the name of the schema.
Answer: Perfect! I’ll enable the draft artifacts feature and use “payments” as the group ID and “MoneyTransfer” as the artifact ID (matching the schema name).
Let me first enable the draft artifacts feature:
[update_configuration_property]
Great! Draft artifacts are now enabled. Now I’ll create the “payments” group and then create the MoneyTransfer artifact.
[create_group]
Excellent! The “payments” group has been created. Now I’ll create the MoneyTransfer artifact:
[create_artifact]
Perfect! The MoneyTransfer artifact has been created. Now I’ll create the first version with the schema content in DRAFT state:
[create_version]
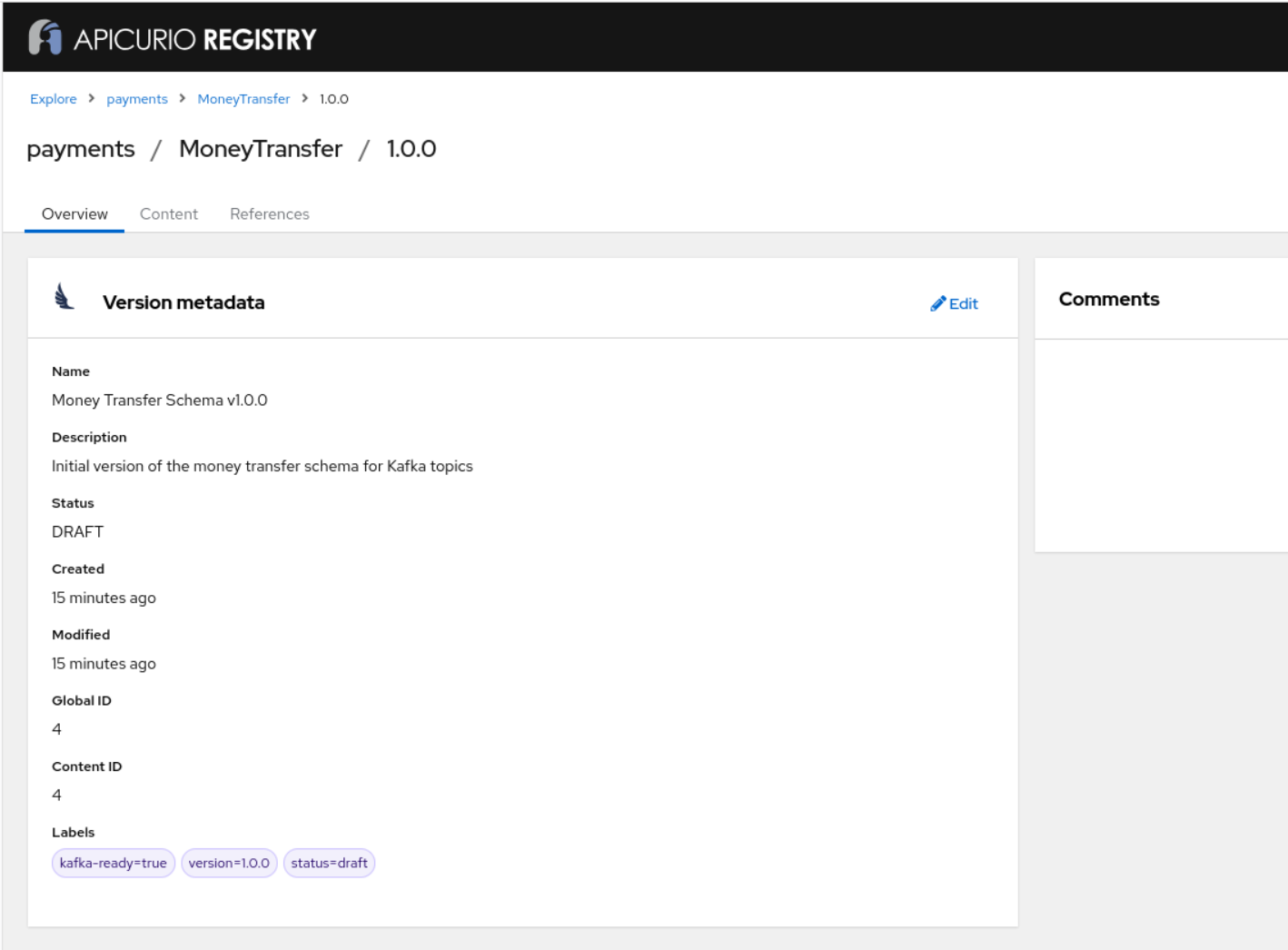
Excellent! 🎉 The MoneyTransfer artifact has been successfully created in DRAFT state. Here’s what we’ve accomplished:
✅ Created:
- Group:
payments(for financial schema organization)- Artifact:
MoneyTransfer(AVRO type)- Version:
1.0.0(in DRAFT state)📋 Schema Details:
- Group ID: payments
- Artifact ID: MoneyTransfer
- Version: 1.0.0
- State: DRAFT (can be modified)
- Global ID: 4
- Content ID: 4
The schema is now stored in the registry and ready for use with Kafka topics. Since it’s in DRAFT state, we can make changes if needed.
Would you like to:
- Make any changes to the schema content?
- Publish it by moving it to ENABLED state?
- Review the current content in the registry?
What would you like to do next?
As expected, the schema appears in our Apicurio Registry instance, but we can still update it:
Let’s make one more edit before we publish the schema - add support for SEPA transfers, and clean up some of the metadata (removed some parts for brevity):
Question Use the draft artifact feature. I want to use group ID “payments” and the artifact ID should be the same as the name of the schema.
Answer: Perfect! I’ll update the schema to support SEPA transfers and clean up the version naming. Let me make these changes:
- Add SEPA support by including SEPA-specific fields and transfer types
- Remove version numbers from the artifact version name and labels
[Money Transfer Avro Schema]
Now let me update the version metadata to remove the version number from the name and labels:
[update_version_metadata]
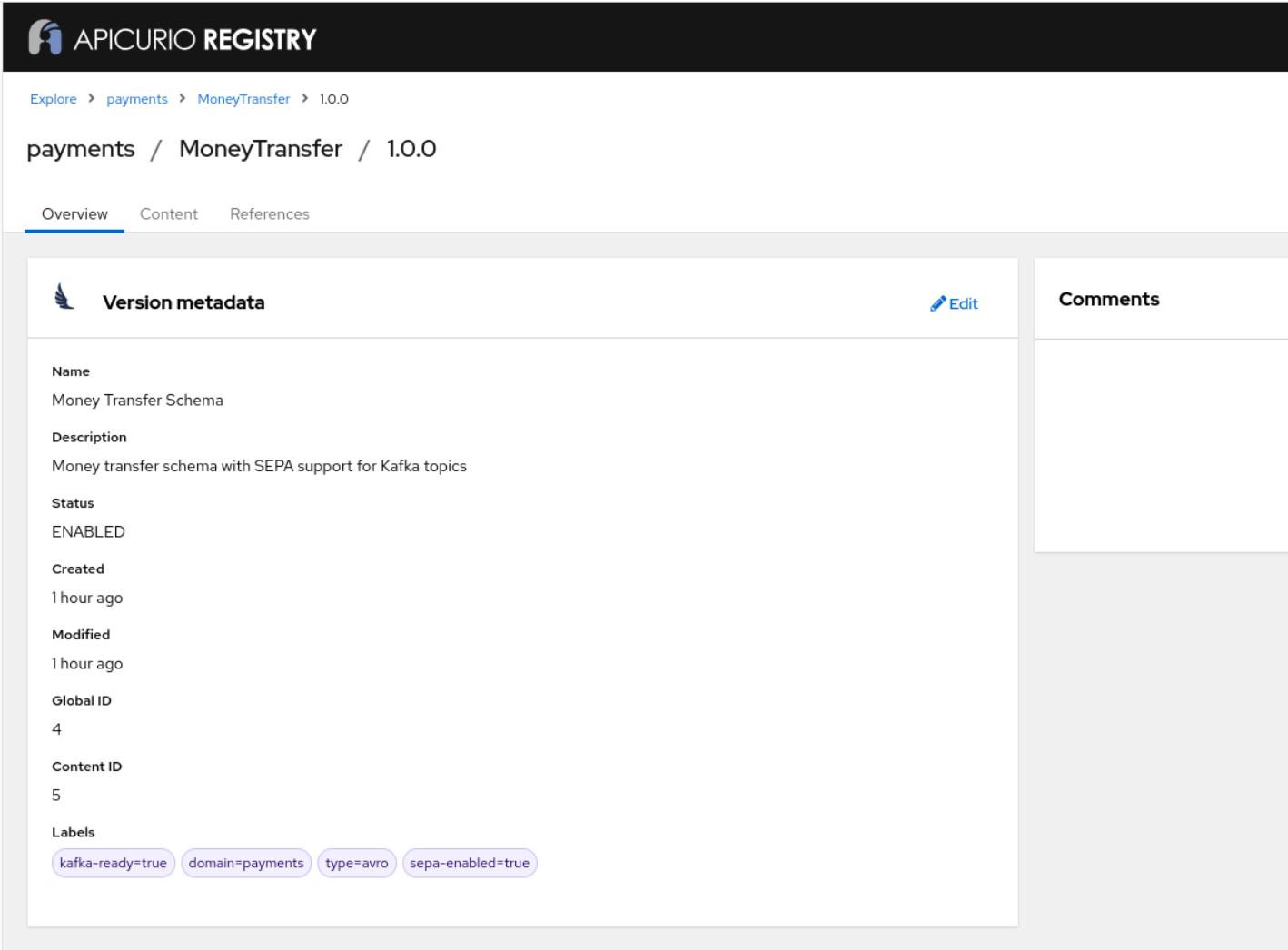
Perfect! ✅ I’ve successfully updated the MoneyTransfer schema with the following changes:
🆕 SEPA Support Added:
New Transfer Types:
SEPA_CREDIT- Standard SEPA credit transfersSEPA_INSTANT- SEPA instant paymentsNew Account Fields:
iban- International Bank Account Number (for SEPA transfers)bic- Bank Identifier Code / SWIFT code (for SEPA transfers)New SEPA-Specific Information:
[…]
🏷️ Cleaned Up Labels & Naming:
- Name: Changed from “Money Transfer Schema v1.0.0” to “Money Transfer Schema”
- Labels: Removed version numbers, added “sepa-enabled”: “true”
- Description: Updated to mention SEPA support
The schema is still in DRAFT state, so we can make additional changes if needed. The schema now fully supports both traditional transfers (domestic, international, wire) and European SEPA transfers with all the required fields.
Would you like to:
- Make any other changes to the schema?
- Publish it by moving it to ENABLED state?
- Review the final schema content?
What would you like to do next?
We see that we can iterate this way until the schema is ready, editing both the content and the metadata. Let’s publish the schema!
Question Publish.
Answer: Perfect! I’ll publish the schema by moving it from DRAFT to ENABLED state.
[update_version_state]
🎉 Successfully Published!
The MoneyTransfer schema has been moved to ENABLED state and is now ready for production use.
📋 Final Artifact Summary:
- Group ID:
payments- Artifact ID:
MoneyTransfer- Version:
1.0.0- State:
ENABLED✅- Type:
AVRO- Global ID:
4🚀 Ready for Kafka Integration:
Your schema is now published and can be used with:
- Kafka producers to serialize money transfer events
- Kafka consumers to deserialize money transfer events
- Schema validation for incoming transfer data
- Schema evolution for future updates
💡 Key Features Included:
- ✅ Standard money transfers (domestic, international, wire)
- ✅ SEPA transfers (credit & instant)
- ✅ IBAN/BIC support for European banking
- ✅ Precise decimal amounts with proper currency handling
- ✅ Comprehensive account information
- ✅ Transfer status tracking
- ✅ Extensible metadata support
The schema is now live in your Apicurio Registry and ready to be consumed by your Kafka applications! 🎯
How to get started
-
We need a running Apicurio Registry instance. The easiest way is to use Docker or Podman to run Apicurio Registry 3 locally:
# API server docker run --rm -it -p 8080:8080 quay.io/apicurio/apicurio-registry:latest-snapshot # UI server docker run --rm -it -p 8888:8080 quay.io/apicurio/apicurio-registry-ui:latest-snapshotNOTE: You can replace
dockerwithpodmanin all commands throughout this guide. -
Multiple LLM providers support the MCP protocol, but to follow this blog post and use Claude, register for Claude AI if you don’t have an account yet.
-
Install the Claude Desktop application. If you are using a system that is not officially supported, like Fedora, unofficial installation options are available. Alternatively, some IDEs such as VS Code support integration with an MCP server.
-
Run Claude Desktop, and go to File > Settings… > Developer > Edit Config, to open the configuration file (e.g.
~/.config/Claude/claude_desktop_config.json). -
Update the configuration file as follows (using Docker or Podman):
{ "mcpServers": { "Apicurio Registry": { "command": "docker", "args": [ "run", "-i", "--rm", "--network=host", "quay.io/apicurio/apicurio-registry-mcp-server:latest-snapshot" ] } } }NOTE: Replace
"command": "docker"with"command": "podman"if you prefer to use Podman.
NOTE: The Apicurio Registry MCP Server source code lives in the Apicurio Registry GitHub repository, where you can also find the most recent README file with additional information, such as configuration options and how to build the MCP server from source.
As of writing of this article, Apicurio Registry MCP server currently supports a wide range of operations for managing your Apicurio Registry content:
- Artifact Types: Listing supported types.
- Configuration Properties: Getting, listing, and updating dynamic configuration properties.
- Groups: Creating, getting, listing, searching, and updating groups.
- Artifacts: Creating, getting, listing, searching, and updating artifacts and their metadata.
- Versions: Creating, getting content, listing, searching, updating metadata, and even updating the state or content of artifact versions.
but there are still more capabilities to add, such as managing content rules, adding comments, import & export, and additional configuration options. We’d love if you decide to take a look at the source code and contribute a PR!
Implementing your own MCP server
In conclusion, I’d like to provide some thoughts and lessons-learned during the implementation of the MCP server.
-
Safety first - Since MCP tools can provide executable functionality that can be destructive or non-reversible (e.g., data deletion), the author of the MCP server has to be careful when implementing such operations. Claude Desktop shows the user a prompt before executing any tool, but that should only be the first line of defense against the LLM making a mistake. We suggest additional precautions such as:
- Carefully worded tool descriptions and prompts
- Sanity checks by the MCP server (e.g., limit the amount of data that can be deleted)
- Requiring configuration options to enable potentially unsafe operations
- Backups
Apicurio Registry MCP server does not yet support delete operations, but it can update configuration properties. As a precaution, only the configuration property enabling draft artifact versions can be modified, unless the MCP server is configured otherwise.
-
Paging is hard - The MCP server communicates with Apicurio Registry using the REST API where some of the operations are paged. We were unable to help Claude understand how to work with paged results, so the MCP server has to request large pages by default.
-
Quarkus is great! - The server has been implemented using the Quarkus MCP Server extension, which made it very easy to define tools and prompts using just a couple of annotations. The most time-consuming part was writing descriptions for the LLM to help it understand Apicurio Registry concepts.
-
Ask the LLM itself to assist you with writing prompts! Plain and direct sentences, lots of examples, and text formatting worked for us.