As promised in the announcement blog about the upcoming release of Apicurio Registry 3.0, this post is a deep dive into the changes we’re making to our Kafka storage variant. We’ll get into what the KafkaSQL storage variant is and why you might want to use it (pros and cons). And importantly, we’ll discuss the significant changes we’ve made to the implementation of this feature for 3.0.
What is the KafkaSQL storage variant?
Of course, Apicurio Registry requires some form of storage in order to persist the content and metadata of artifacts and versions. We currently support two different storage variants:
- SQL (Postgresql or SQL Server)
- Kafka
While storing data in a SQL database is obvious (and is recommended for most use cases), it can be useful to instead store registry data in a Kafka topic. The KafkaSQL storage variant provides such a feature.
Why use Kafka for storage?
Even though we recommend using a database as the storage variant for Registry, there are cases where using Kafka instead can make sense. The most obvious one is that some organizations have significant expertise managing Kafka clusters, but do not have similar expertise with relational databases. It can be extremely convenient, when using Apicurio Registry as a Kafka Schema Registry, to use Kafka for registry storage (since you would obviously already have a working Kafka cluster).
How does KafkaSQL work?
The implementation of KafkaSQL is fairly simple: a persistent Kafka topic is used to communicate (and save) all data changes. You can think of this Kafka topic as a journal containing all changes to the registry. Whenever a user creates a new artifact, changes its metadata, adds a new version, or configures a rule, information about that change is published to the Kafka topic.
At the same time, Apicurio Registry is a consumer of the same topic. Whenever a message is published, Registry will consume it and update an internal H2 SQL database with that information. This not only provides persistence (the Kafka topic must be properly configured) but also allows multiple Registry instances (typically kubernetes/openshift pods) to each have a full copy of the Registry state in memory at the same time.
The flow is therefore this:
Change operation is received by Registry (HTTP Request Thread)
- An HTTP request is received representing a registry data change
- The change is turned into a Kafka message
- The Kafka message is published to the Kafka topic (the journal)
- The thread waits for the message to be consumed
Registry Kafka consumer thread consumes messages from the Kafka topic (Consumer Thread)
- The message is consumed from the kafka topic
- The message is converted to an internal SQL statement
- The SQL statement is applied to the internal H2 database
- The Request Thread is notified that the message was processed
Waiting request wakes up and responds (HTTP Request Thread continued)
- The thread wakes up and responds to the originating HTTP request
Once nice thing about this implementation is that all read requests are handled the same way for both the SQL and KafkaSQL storage variants. In both cases we simply query the SQL database for the information (either the PostgreSQL database for the SQL variant or the internal H2 database for the KafkaSQL variant).
What are the pros and cons of using KafkaSQL?
Pros
- You can store your registry data without provisioning and maintaining a SQL database.
- Read requests scale extremely well (linearly) with the number of Registry pods you provision.
Cons
- Registry pod startup times get slower and slower as the system ages, because all messages on the Kafka topic must be consumed on startup.
- Data backup/restore might be harder for Kafka topics vs. a SQL database.
- Fixing data corruption issues is much harder because you cannot simply run some SQL commands to modify data directly in the storage.
What are the KafkaSQL implementation changes in 3.0?
In Registry version 2.x, our approach to the structure of the Kafka messages was based on Kafka topic log compaction. Log compaction works well for data streams where more recent messages completely replace the data of old messages. In such systems, only the latest message is important. Even though that’s not exactly how we have structured our data model, we attempted to model our data as best we could to fit the log compaction approach. This approach worked to some degree, but we had a number of edge cases that made it challenging. It was also an approach that was difficult to maintain: every change to the storage layer needed to be really thought about, since a bug in the way we structured our Kafka messages could easily result in permanent data loss due to log compaction.
No more log compaction…
For the reasons explained above, we have decided to completely change the organization/structure of our Kafka messages. Instead of trying to organize our data into a log-compaction compatible structure, we are now creating the Kafka messages in more of an RPC style.
Essentially we are creating a one-to-one mapping between (write) methods
in our RegistryStorage interface and messages on the Kafka journal topic.
This makes maintaining both storage variants extremely easy, but it means
that we are no longer taking advantage of log compaction (since the
messages are no longer structured in that way). The major consequence
of this change is that the number of messages on the Kafka topic is
even greater than before, potentially resulting in even longer pod
startup times (since it continues to be true that on startup a pod
must consume all messages on the topic to fully reproduce the state).
We already needed a solution to that problem, and now we need it even more! Which leads us to…
State snapshots…for speed!
As already discussed in this blog, whenever a new instance of Registry is started pointing to an existing journal topic, it has to process every single message to restore the internal state of the application that is used for reads. This has two main effects:
- In the event of data loss in the topic, there is no backup strategy (by default)
- It causes the replica start to be fairly slow (depending on the topic size, of course).
To address these problems, a new feature has been implemented in Registry 3.x: snapshots of the internal store.
The way snapshots work in Registry 3 is that, when a (POST) call to the
endpoint /admin/snapshots is made, a new snapshot of the internal
store is created. This is done by sending a snapshot marker message
with a snapshot id (randomly generated) to the journal topic. This
marker message represents a request for a new snapshot to be created.
After this, the consumer thread (the same thread that is responsible for processing all the other messages) reads the marker message and creates a SQL dump of the internal store. The SQL dump is created in a location that can be configured using the following property:
- System property:
apicurio.storage.snapshot.location - Environment variable:
APICURIO_STORAGE_SNAPSHOT_LOCATION
(Note: The default value for this property is /tmp)
Once the SQL dump is created, a message is published to the snapshots Kafka topic. The message includes the location of the snapshot and the snapshotId (as the message key). The snapshots topic is used to keep track of all the created snapshots. This means that, as you might be already thinking, in Registry 3 you will need to create and configure two Kafka topics instead of just one:
- Journal topic (one message for each write operation)
- Snapshots topic (one message for each created snapshot)
Once the snapshot has been created, when a new replica is created (or an
existing replica is restarted), the messages on the snapshots topic are consumed
in order to find the most recent snapshot. If there is a snapshot present,
the application loads the SQL dump retrieved from the location in the message and
uses it to restore the internal database. This dramatically improves the application
startup time, since the internal state is restored by issuing a single SQL command
(H2 RESTORE TO) instead of processing every single message present in the journal
topic.
Once the database has been restored, the consumer thread starts consuming the messages present in the journal topic, discarding all the messages until the corresponding snapshot marker message is found. All remaining messages (those messages on the journal topic that follow the snapshot marker message) are processed as normal and dispatched to the SQL store as appropriate.
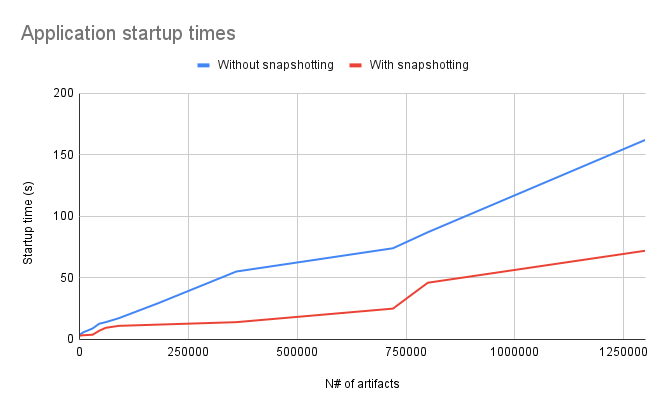
With this new feature you can now set up a backup strategy of your Apicurio Registry data when Kafka is used as the storage option, preventing potential data loss and also improving replica startup time.
Finally, here are two graphics comparing the startup times with and without snapshotting. In the snapshot graph snapshots were created for each 250.000 artifacts: