
Apicurio Registry allows to manage artifacts with references as shown in the documentation. One of the cool features we’ve added on top of this is the possibility of using a dereference parameter for certain API endpoints that optionally allows you to fetch the full content of an artifact with all the references inlined within the same content. This is especially useful in certain contexts to reduce the number of HTTP requests in the Kafka Serializers and Deserializers, as you will see in this blog.
Intro
The code example used for this blog post can be found in the Apicurio Registry examples.
One of the limitations of the JSON Schema format is that you cannot discover the full schema from some data that adheres to the schema. That’s the main reason why, for this serde, the schema being used has to be registered upfront, and that’s what you see in the code example from line 57 to line 132. where the main schema city.json is registered with all the references in the hierarchy. Along those lines, a full hierarchy of schemas is registered in Apicurio Registry. The hierarchy can be described as follows and represented as a tree:
citizen
| | |
city qualification citizenIdentifier
| |
qualification qualification
As you may notice, there are three different files with the same name. This is done on purpose to demonstrate that you can have different schemas with the same name within the same hierarchy. When they’re registered in the code example, they’re registered under the same group but using different artifact ids, so they can be referenced from their main schema.
Since an image is way better than trying to describe it, this is the structure in the file system:
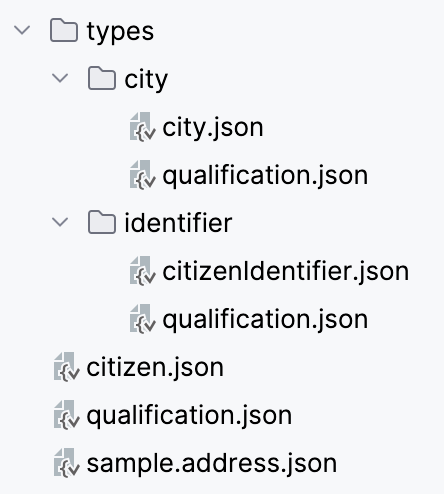
In the code example there are also java classes that represent each of the objects we have in the structure, so we can use them when producing Kafka messages. There is one Java class per each JSON Schema file.
Using the REST API
Although the example above uses the Apicurio Registry Java client to register the full hierarchy of schemas, it’s also possible to use the REST API. Note that, when an artifact with references is created, the artifact content itself in the request must be quoted. Here’s a set of Curl commands that delivers this result:
First we must start creating the leaves, in this case, those are the city qualification and the citizenIdentifier qualification:
//Creates the city qualification
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/' \
--header 'X-Registry-ArtifactId: cityQualification' \
--header 'Content-Type: application/json; artifactType=JSON' \
--data '{
"$id": "https://example.com/types/city/qualification.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Qualification",
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The subject'\''s name"
},
"qualification": {
"type": "integer",
"description": "The city qualification",
"minimum": 10
}
}
}'
//Creates the citizen identifier qualification
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/' \
--header 'X-Registry-ArtifactId: identifierQualification' \
--header 'Content-Type: application/json; artifactType=JSON' \
--data '{
"$id": "https://example.com/types/identifier/qualification.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Qualification",
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The subject'\''s name"
},
"qualification": {
"type": "integer",
"description": "The identifier qualification",
"minimum": 20
}
}
}'
Once the leaves are created, we can go up through the hierarchy, creating the schemas that will be referenced by the citizen. First we create the city schema:
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/' \
--header 'X-Registry-ArtifactId: city' \
--header 'Content-Type: application/create.extended+json' \
--header 'X-Registry-ArtifactType: JSON' \
--data '{
"content": "{\r\n \"$id\": \"https:\/\/example.com\/types\/city\/city.json\",\r\n \"$schema\": \"http:\/\/json-schema.org\/draft-07\/schema#\",\r\n \"title\": \"City\",\r\n \"type\": \"object\",\r\n \"properties\": {\r\n \"name\": {\r\n \"type\": \"string\",\r\n \"description\": \"The city'\''s name.\"\r\n },\r\n \"zipCode\": {\r\n \"type\": \"integer\",\r\n \"description\": \"The zip code.\",\r\n \"minimum\": 0\r\n },\r\n \"qualification\": {\r\n \"$ref\": \"qualification.json\"\r\n }\r\n }\r\n}",
"references": [
{
"name": "qualification.json",
"groupId": "default",
"artifactId": "cityQualification",
"version": "1"
}
]
}'
Then the citizen identifier schema:
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/' \
--header 'X-Registry-ArtifactId: citizenIdentifier' \
--header 'Content-Type: application/create.extended+json' \
--header 'X-Registry-ArtifactType: JSON' \
--data '{
"content": "{\r\n \"$id\": \"https:\/\/example.com\/types\/identifier\/citizenIdentifier.json\",\r\n \"$schema\": \"http:\/\/json-schema.org\/draft-07\/schema#\",\r\n \"title\": \"Identifier\",\r\n \"type\": \"object\",\r\n \"properties\": {\r\n \"identifier\": {\r\n \"type\": \"integer\",\r\n \"description\": \"The citizen identifier.\",\r\n \"minimum\": 0\r\n },\r\n \"qualification\": {\r\n \"$ref\": \"qualification.json\"\r\n }\r\n }\r\n}",
"references": [
{
"name": "qualification.json",
"groupId": "default",
"artifactId": "identifierQualification",
"version": "1"
}
]
}'
The citizen qualification schema:
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/' \
--header 'X-Registry-ArtifactId: qualification' \
--header 'Content-Type: application/json; artifactType=JSON' \
--data '{
"$id": "https://example.com/qualification.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Qualification",
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The subject'\''s name"
},
"qualification": {
"type": "integer",
"description": "The qualification.",
"minimum": 0
}
}
}'
And, finally, the citizen schema itself with references to qualification, city and identifier
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/' \
--header 'X-Registry-ArtifactId: citizen' \
--header 'Content-Type: application/create.extended+json' \
--header 'X-Registry-ArtifactType: JSON' \
--data '{
"content": "{\r\n \"$id\": \"https:\/\/example.com\/citizen.json\",\r\n \"$schema\": \"http:\/\/json-schema.org\/draft-07\/schema#\",\r\n \"title\": \"Citizen\",\r\n \"type\": \"object\",\r\n \"properties\":{\r\n\"firstName\": {\r\n \"type\": \"string\",\r\n \"description\": \"The citizen'\''s first name.\"\r\n },\r\n\"lastName\": {\r\n \"type\": \"string\",\r\n \"description\": \"The citizen'\''s last name.\"\r\n },\r\n \"age\": {\r\n\"description\": \"Age in years which must be equal to or greater than zero.\",\r\n \"type\": \"integer\",\r\n\"minimum\": 0\r\n },\r\n \"city\": {\r\n \"$ref\": \"types\/city\/city.json\"\r\n },\r\n \"identifier\": {\r\n\"$ref\": \"types\/identifier\/citizenIdentifier.json\"\r\n },\r\n \"qualifications\": {\r\n \"type\": \"array\",\r\n\"items\": {\r\n \"$ref\": \"qualification.json\"\r\n }\r\n }\r\n },\r\n \"required\": [\r\n \"city\"\r\n ]\r\n}",
"references": [
{
"name": "qualification.json",
"groupId": "default",
"artifactId": "qualification",
"version": "1"
},
{
"name": "types/city/city.json",
"groupId": "default",
"artifactId": "city",
"version": "1"
},
{
"name": "types/identifier/citizenIdentifier.json",
"groupId": "default",
"artifactId": "citizenIdentifier",
"version": "1"
},
{
"name": "sample.address.json",
"groupId": "default",
"artifactId": "address",
"version": "1"
}
]
}'
JSON Schema dereference
By default, the endpoints that return the content of a particular artifact fetch just the main content, and then you must get the links to the references and, one by one, do a full scan of the hierarchy to fetch any other sub-schema needed. For instance, the content of the city.json schema is the following:
{
"$id": "https://example.com/citizen.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Citizen",
"type": "object",
"properties": {
"firstName": {
"type": "string",
"description": "The citizen's first name."
},
"lastName": {
"type": "string",
"description": "The citizen's last name."
},
"age": {
"description": "Age in years which must be equal to or greater than zero.",
"type": "integer",
"minimum": 0
},
"city": {
"$ref": "types/city/city.json"
},
"identifier": {
"$ref": "types/identifier/citizenIdentifier.json"
},
"qualifications": {
"type": "array",
"items": {
"$ref": "qualification.json"
}
}
},
"required": [
"city"
]
}
Without dereferencing in order to be able to produce Kafka messages to adhere to this schema, that is already registered in Apicurio Registry, we would need to fetch all the nested references with multiple HTTP requests and then parse all of them while, when dereferencing is used, this is what you get:
{
"$schema" : "http://json-schema.org/draft-07/schema#",
"title" : "Citizen",
"type" : "object",
"properties" : {
"firstName" : {
"description" : "The citizen's first name.",
"type" : "string"
},
"lastName" : {
"description" : "The citizen's last name.",
"type" : "string"
},
"identifier" : {
"title" : "Identifier",
"type" : "object",
"properties" : {
"identifier" : {
"description" : "The citizen identifier.",
"type" : "integer",
"minimum" : 0
},
"qualification" : {
"title" : "Qualification",
"type" : "object",
"properties" : {
"qualification" : {
"description" : "The identifier qualification",
"type" : "integer",
"minimum" : 20
},
"name" : {
"description" : "The subject's name",
"type" : "string"
}
}
}
}
},
"qualifications" : {
"type" : "array",
"items" : {
"title" : "Qualification",
"type" : "object",
"properties" : {
"qualification" : {
"description" : "The qualification.",
"type" : "integer",
"minimum" : 0
},
"name" : {
"description" : "The subject's name",
"type" : "string"
}
}
}
},
"city" : {
"title" : "City",
"type" : "object",
"properties" : {
"zipCode" : {
"description" : "The zip code.",
"type" : "integer",
"minimum" : 0
},
"qualification" : {
"title" : "Qualification",
"type" : "object",
"properties" : {
"qualification" : {
"description" : "The city qualification",
"type" : "integer",
"minimum" : 10
},
"name" : {
"description" : "The subject's name",
"type" : "string"
}
}
},
"name" : {
"description" : "The city's name.",
"type" : "string"
}
}
},
"age" : {
"description" : "Age in years which must be equal to or greater than zero.",
"type" : "integer",
"minimum" : 0
}
},
"required" : [ "city" ],
"$id" : "https://example.com/citizen.json"
}
As you can see, that’s the content of the full hierarchy, not just the schema of the citizen element alone. There are two endpoints where you can get the content dereferenced, with the following curl commands:
curl --location 'http://localhost:8080/apis/registry/v2/ids/globalIds/6?dereference=true'
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/JsonSerdeReferencesExample?dereference=true'
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/JsonSerdeReferencesExample/versions/1?dereference=true'
Referencing options ===
Note that, even though referencing a whole schema definition is the most common use case, it’s also possible to reference a single object definition defined in a json file with multiple schemas. For example, we might have the following schema definition:
{
"$id": "https://example.com/types/all-types.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"definitions": {
"City": {
"title": "City",
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The city's name."
},
"zipCode": {
"type": "integer",
"description": "The zip code.",
"minimum": 0
}
}
},
"Identifier": {
"title": "Identifier",
"type": "object",
"properties": {
"identifier": {
"type": "integer",
"description": "The citizen identifier.",
"minimum": 0
}
}
}
}
}
With definitions for both an identifier and the city objects. Then we might decide that we want to have a separate schema that points to an entire definition, like the one below:
{
"$id": "https://example.com/citizen.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Citizen",
"type": "object",
"properties": {
"firstName": {
"type": "string",
"description": "The citizen's first name."
},
"lastName": {
"type": "string",
"description": "The citizen's last name."
},
"age": {
"description": "Age in years which must be equal to or greater than zero.",
"type": "integer",
"minimum": 0
},
"city": {
"$ref": "types/all-types.json#/definitions/City"
},
"identifier": {
"$ref": "types/all-types.json#/definitions/Identifier"
}
},
"required": [
"city"
]
}
Or we might decide to just reference a single property inside a schema definition, like the schema below does:
{
"$id": "https://example.com/citizen.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Citizen",
"type": "object",
"properties": {
"firstName": {
"type": "string",
"description": "The citizen's first name."
},
"lastName": {
"type": "string",
"description": "The citizen's last name."
},
"age": {
"description": "Age in years which must be equal to or greater than zero.",
"type": "integer",
"minimum": 0
},
"city": {
"$ref": "types/all-types.json#/definitions/City/properties/name"
},
"identifier": {
"$ref": "types/all-types.json#/definitions/Identifier"
}
},
"required": [
"city"
]
}
The three options work exactly the same way when it comes to registering those schemas using the REST API as if we were registering a schema that references another. First we must register the schema that will be referenced, in this case, the one with the definitions:
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/' \
--header 'X-Registry-ArtifactId: all-types' \
--header 'Content-Type: application/json; artifactType=JSON' \
--data '{
"$id": "https://example.com/types/all-types.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"definitions": {
"City": {
"title": "City",
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The city'\''s name."
},
"zipCode": {
"type": "integer",
"description": "The zip code.",
"minimum": 0
},
"qualification": {
"$ref": "city/qualification.json"
}
}
},
"Identifier": {
"title": "Identifier",
"type": "object",
"properties": {
"identifier": {
"type": "integer",
"description": "The citizen identifier.",
"minimum": 0
},
"qualification": {
"$ref": "identifier/qualification.json"
}
}
}
}
}'
Once this schema has been registered, we can now decide to register two separate schemas, the first one referencing the entire city object:
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts' \
--header 'X-Registry-ArtifactId: citizen-object-level' \
--header 'Content-Type: application/create.extended+json' \
--header 'X-Registry-ArtifactType: JSON' \
--data '{
"content": "{\r\n \"$id\": \"https:\/\/example.com\/citizen.json\",\r\n \"$schema\": \"http:\/\/json-schema.org\/draft-07\/schema#\",\r\n \"title\": \"Citizen\",\r\n \"type\": \"object\",\r\n \"properties\": {\r\n \"firstName\": {\r\n \"type\": \"string\",\r\n \"description\": \"The citizen'\''s first name.\"\r\n },\r\n \"lastName\": {\r\n \"type\": \"string\",\r\n \"description\": \"The citizen'\''s last name.\"\r\n },\r\n \"age\": {\r\n \"description\": \"Age in years which must be equal to or greater than zero.\",\r\n \"type\": \"integer\",\r\n \"minimum\": 0\r\n },\r\n \"city\": {\r\n \"$ref\": \"types\/all-types.json#\/definitions\/City\"\r\n },\r\n \"identifier\": {\r\n \"$ref\": \"types\/all-types.json#\/definitions\/Identifier\"\r\n }\r\n },\r\n \"required\": [\r\n \"city\"\r\n ]\r\n}",
"references": [
{
"name": "types/all-types.json#/definitions/City",
"groupId": "default",
"artifactId": "all-types",
"version": "1"
},
{
"name": "types/all-types.json#/definitions/Identifier",
"groupId": "default",
"artifactId": "all-types",
"version": "1"
}
]
}'
And then register the second schema, where just the city name property is referenced:
curl --location 'http://localhost:8080/apis/registry/v2/groups/default/artifacts' \
--header 'X-Registry-ArtifactId: citizen-property-level' \
--header 'Content-Type: application/create.extended+json' \
--header 'X-Registry-ArtifactType: JSON' \
--data '{
"content": "{\r\n \"$id\": \"https:\/\/example.com\/citizen.json\",\r\n \"$schema\": \"http:\/\/json-schema.org\/draft-07\/schema#\",\r\n \"title\": \"Citizen\",\r\n \"type\": \"object\",\r\n \"properties\": {\r\n \"firstName\": {\r\n \"type\": \"string\",\r\n \"description\": \"The citizen'\''s first name.\"\r\n },\r\n \"lastName\": {\r\n \"type\": \"string\",\r\n \"description\": \"The citizen'\''s last name.\"\r\n },\r\n \"age\": {\r\n \"description\": \"Age in years which must be equal to or greater than zero.\",\r\n \"type\": \"integer\",\r\n \"minimum\": 0\r\n },\r\n \"city\": {\r\n \"$ref\": \"types\/all-types.json#\/definitions\/City\/properties\/name\"\r\n },\r\n \"identifier\": {\r\n \"$ref\": \"types\/all-types.json#\/definitions\/Identifier\"\r\n }\r\n },\r\n \"required\": [\r\n \"city\"\r\n ]\r\n}",
"references": [
{
"name": "types/all-types.json#/definitions/City/properties/name",
"groupId": "default",
"artifactId": "all-types",
"version": "1"
},
{
"name": "types/all-types.json#/definitions/Identifier",
"groupId": "default",
"artifactId": "all-types",
"version": "1"
}
]
}'
The most relevant part here is the name of the reference (apart from the content itself, of course). The name of the reference is what’s going to determine the part of the schema to be used to fill the reference in the main content. In the first case, in the object scenario, the reference name is types/all-types.json#/definitions/City creating a reference to the all-types.json file in general, and to the city definition in particular. In the second scenario, the property path is used for the reference name types/all-types.json#/definitions/City/properties/name, creating a reference to the all-types.json file in general, and to the city name in particular.
This is especially important for dereferencing content, since the final result will be different for each schema. In the object scenario, the city object will be inlined within the main schema as follows:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Citizen",
"type": "object",
"properties": {
"firstName": {
"description": "The citizen's first name.",
"type": "string"
},
"lastName": {
"description": "The citizen's last name.",
"type": "string"
},
"identifier": {
"title": "Identifier",
"type": "object",
"properties": {
"identifier": {
"description": "The citizen identifier.",
"type": "integer",
"minimum": 0
}
}
},
"city": {
"title": "City",
"type": "object",
"properties": {
"zipCode": {
"description": "The zip code.",
"type": "integer",
"minimum": 0
},
"name": {
"description": "The city's name.",
"type": "string"
}
}
},
"age": {
"description": "Age in years which must be equal to or greater than zero.",
"type": "integer",
"minimum": 0
}
},
"required": [
"city"
],
"$id": "https://example.com/citizen.json"
}
Whereas in the second scenario, the property one, just the city name will be inlined:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Citizen",
"type": "object",
"properties": {
"firstName": {
"description": "The citizen's first name.",
"type": "string"
},
"lastName": {
"description": "The citizen's last name.",
"type": "string"
},
"identifier": {
"title": "Identifier",
"type": "object",
"properties": {
"identifier": {
"description": "The citizen identifier.",
"type": "integer",
"minimum": 0
}
}
},
"city": {
"description": "The city's name.",
"type": "string"
},
"age": {
"description": "Age in years which must be equal to or greater than zero.",
"type": "integer",
"minimum": 0
}
},
"required": [
"city"
],
"$id": "https://example.com/citizen.json"
}
JSON Schema Kafka Serde dereference
Now, in order to make good use of all of this, we can use a Kafka producer. For this example, in the Kafka Producer there is one extremely important property we must set, the schema resolver configuration option SERIALIZER_DEREFERENCE_SCHEMA. This is the option that will instruct the Schema Resolver to use the dereference parameter in the globalIds endpoint above (since that is the endpoint used by default to resolve the schema).
Properties props = new Properties();
// Configure kafka settings
props.putIfAbsent(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, SERVERS);
props.putIfAbsent(ProducerConfig.CLIENT_ID_CONFIG, "Producer-" + TOPIC_NAME);
props.putIfAbsent(ProducerConfig.ACKS_CONFIG, "all");
props.putIfAbsent(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.putIfAbsent(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSchemaKafkaSerializer.class.getName());
props.putIfAbsent(SerdeConfig.ARTIFACT_RESOLVER_STRATEGY, SimpleTopicIdStrategy.class.getName());
props.putIfAbsent(SerdeConfig.EXPLICIT_ARTIFACT_GROUP_ID, "default");
props.putIfAbsent(SerdeConfig.REGISTRY_URL, REGISTRY_URL);
//This is the most important configuration for this particular example.
props.putIfAbsent(SchemaResolverConfig.SERIALIZER_DEREFERENCE_SCHEMA, true);
// Create the Kafka producer
Producer<Object, Object> producer = new KafkaProducer<>(props);
With this producer we can then send messages to Kafka that adhere to the citizen schema as follows:
for(int idx = 0; idx < 5; idx++) {
City city=new City("New York",10001);
city.setQualification(new CityQualification("city_qualification",11));
CitizenIdentifier identifier=new CitizenIdentifier(123456789);
identifier.setIdentifierQualification(new IdentifierQualification("test_subject",20));
Citizen citizen=new Citizen("Carles","Arnal",23,city,identifier,List.of(new Qualification(UUID.randomUUID().toString(),6),new Qualification(UUID.randomUUID().toString(),7),new Qualification(UUID.randomUUID().toString(),8)));
// Send/produce the message on the Kafka Producer
ProducerRecord<Object, Object> producedRecord = new ProducerRecord<>(topicName, SUBJECT_NAME, citizen);
producer.send(producedRecord);
}
And consume them with a consumer that is created as follows, instructing the deserializer to use the schema dereferenced with the following configuration property DESERIALIZER_DEREFERENCE_SCHEMA:
Properties props = new Properties();
props.putIfAbsent(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, SERVERS);
props.putIfAbsent(ConsumerConfig.GROUP_ID_CONFIG, "Consumer-" + TOPIC_NAME);
props.putIfAbsent(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
props.putIfAbsent(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.putIfAbsent(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.putIfAbsent(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.putIfAbsent(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonSchemaKafkaDeserializer.class.getName());
props.putIfAbsent(SerdeConfig.ARTIFACT_RESOLVER_STRATEGY, SimpleTopicIdStrategy.class.getName());
props.putIfAbsent(SerdeConfig.EXPLICIT_ARTIFACT_GROUP_ID, "default");
props.putIfAbsent(SerdeConfig.VALIDATION_ENABLED, true);
//This is the most important configuration for this example, that instructs the deserializer to fetch the dereferenced schema.
props.putIfAbsent(SchemaResolverConfig.DESERIALIZER_DEREFERENCE_SCHEMA, true);
// Configure Service Registry location
props.putIfAbsent(SerdeConfig.REGISTRY_URL, REGISTRY_URL);
// No other configuration needed for the deserializer, because the globalId of the schema
// the deserializer should use is sent as part of the payload. So the deserializer simply
// extracts that globalId and uses it to look up the Schema from the registry.
// Create the Kafka Consumer
KafkaConsumer<Long, Citizen> consumer = new KafkaConsumer<>(props);
And then consume the messages with the consumer configured above like this:
while (messageCount < 5) {
final ConsumerRecords<Long, Citizen> records = consumer.poll(Duration.ofSeconds(1));
messageCount += records.count();
if (records.count() == 0) {
// Do nothing - no messages waiting.
System.out.println("No messages waiting...");
} else records.forEach(record -> {
Citizen msg = record.value();
System.out.println("Consumed a message: " + msg + " @ " + msg.getCity());
});
}
Instead of doing an HTTP request to get the citizen schema, another request to fetch the pointers to the references, and, in this case (this process grows with the hierarchy size), another nine requests to discover the full hierarchy, a single HTTP request gets the full content of the hierarchy and then uses it to produce/consume messages.