
One of the major changes introduced in Apicurio Registry 2.x were improvements in the supported storage options.
We have kept the possibility of using both PostgreSQL database and Kafka to store your data, but the internals of the
storage options have been improved, and in some ways simplified.
We have received great feedback from the users of the new KafkaSQL storage option, but recently several users have reported an interesting bug, that seems to only affect users with the KafkaSQL persistence enabled.
The following error appears when a user attempts to update or create a new artifact:
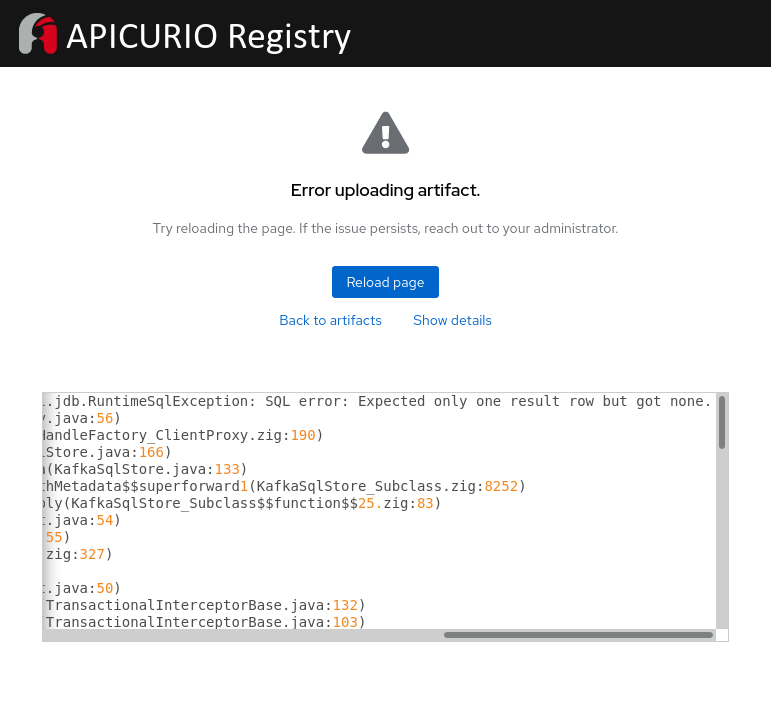
The first time that one of the users saw this error, they were able to resolve it by deleting the Kafka topic where the Apicurio Registry stores its data. However, the error started appearing again after some time. We have investigated the problem, found the cause, and would like to take this opportunity to share the details with the Apicurio community.
In this blog post, we will take a look at the KafkaSQL storage option in more detail.
We’ll describe the bug and the solution, and provide a temporary workaround for users
until they are able to upgrade to the patched version 2.1.4.Final.
KafkaSQL Storage
A major use-case for Apicurio Registry is to manage and distribute schemas for messages in Kafka topics. This means that a lot of our users have a Kafka cluster available, so supporting it as a storage option has been a priority for us.
KafkaSQL storage shares common logic with the standard SQL storage option, but does not use a central SQL database to store Apicurio Registry data. Instead, each node uses a local SQL database. To keep the replicas in sync, each change in one of the local databases is replicated to the other nodes in the cluster using a Kafka topic. This makes the read operations on the data straightforward, and allows us to keep the commonality with the SQL persistence option.
The design of the Kafka messages closely follows the tables that are used both in the local SQL database, and the database for the standard SQL storage.
Each Kafka message has a key and a corresponding value. Kafka itself is agnostic about their content, and treats them as a byte array. In the KafkaSQL storage, they are represented by objects that are serialized into a JSON String, prepended with marker bytes used to recognize message type.
In general, each message value class has a corresponding key class.
Classes for the keys are mainly responsible for determining the partition that the message is going to reside in,
the tenant information in case of a multi-tenant deployment, and identifying information for the object that the message value represents.
For example ArtifactVersionKey contains group ID, artifact ID and version identifiers for the given artifact version object.
Choice of the partition key is important for maintaining consistency of the data between nodes,
because ordering of the messages is only guaranteed in the same partition.
Classes for the values contain a field with the operation that the message represents, which includes CREATE, UPDATE, and DELETE.
The other fields carry the rest of the information, such as (for example) the editable metadata for an artifact version.
 KafkaSQL storage option workflow diagram
KafkaSQL storage option workflow diagram
When a change to a piece of data occurs, the originating node creates and sends the message to the Kafka topic, and blocks the user thread until the operation is processed. Its local database is not modified directly. Each node only applies changes that are read form the Kafka topic. Therefore, the user thread is unblocked only after the original message is consumed from the topic by the node. This ensures that in case of a composite operation, messages are always processed in the correct order, and critically in the same order for each node.
For example, when adding a new artifact version, the user may store a new content that is not already present in the storage. Therefore, the operation usually consists of two messages that have to be kept in the correct order, or the artifact version wouldn’t be able to reference the new content.
An important thing to note is that when a node is restarted, and its local SQL database is empty,
simply reading all the messages from the kafkasql-journal will replicate the data that is already present on other live nodes.
This works even when the entire Apicurio Registry application is stopped and restarted,
as long as the data in the kafkasql-journal topic remains persisted and backed up.
Investigation
In order to investigate the issue, we have to first attempt to reproduce the issue on a local Apicurio Registry deployment with KafkaSQL storage. The following is a list of steps we have performed.
First, a local Kafka instance must be downloaded, and then we can run it:
Start Zookeper:
bin/zookeeper-server-start.sh config/zookeeper.properties
and the start Kafka:
bin/kafka-server-start.sh config/server.properties
We have been able to get the contents of the Kafka topics from one the users who reported the issue. They used Kafkacat tool to export the data. An example output of Kafkacat looks like this:
{"topic":"kafkasql-journal","partition":0,"offset":0,"tstype":"create","ts":1637230546039,"headers":["req","ef7fd699-2311-4ba6-9d5a-f9087815eb83"],"key":"\u0000{\"bootstrapId\":\"24240819-0738-49a7-8ab2-2b971176b0e1\"}","payload":null}
{"topic":"kafkasql-journal","partition":0,"offset":1,"tstype":"create","ts":1637230571121,"headers":["req","9520eb8f-23a4-40f4-99a0-9d917406f700"],"key":"\u0001{\"tenantId\":\"_\",\"ruleType\":\"VALIDITY\"}","payload":"\u0001{\"action\":\"CREATE\",\"config\":{\"configuration\":\"FULL\"}}"}
{"topic":"kafkasql-journal","partition":0,"offset":3,"tstype":"create","ts":1637230581768,"headers":["req","2a897033-111e-4fdf-a3cc-02941a9db84f"],"key":"\u0002{\"tenantId\":\"_\",\"contentHash\":\"377072c58f3999d1e42455c1cf2563d4e5a367c3ee66a5be41ac376902183bc4\",\"contentId\":1}","payload":"\u0002\u0001\u0000\u0000\u0000@9e15d06c0aa184746bc092841d0a0efd0ce276c5d36873bf471482e3401e92ab\u0000\u0000\u0000�{\n \"type\": \"record\",\n \"name\": \"User1\",\n \"namespace\": \"foo\",\n \"fields\": [\n { \"name\": \"active1\", \"type\": [\"null\", \"boolean\"] }\n ]\n}"}
{"topic":"kafkasql-journal","partition":0,"offset":5,"tstype":"create","ts":1637230581843,"headers":["req","2dd94bfb-34a1-4c23-b93c-54242f94aba4"],"key":"\u0003{\"tenantId\":\"_\",\"artifactId\":\"d0c00bec-3e4a-4386-ad67-b23b5a91ce96\",\"uuid\":\"6b50bb64-65ba-4ed8-beaf-deea49a7e610\"}","payload":"\u0003{\"action\":\"CREATE\",\"metaData\":{\"name\":\"User1\"},\"globalId\":1,\"artifactType\":\"AVRO\",\"contentHash\":\"377072c58f3999d1e42455c1cf2563d4e5a367c3ee66a5be41ac376902183bc4\",\"createdBy\":\"\",\"createdOn\":1637230581817}"}
{"topic":"kafkasql-journal","partition":0,"offset":6,"tstype":"create","ts":1637230593970,"headers":["req","9a34b683-02af-4360-8617-1fc5f17c6509"],"key":"\t{\"tenantId\":\"_\"}","payload":"\t{\"action\":\"CREATE\"}"}
{"topic":"kafkasql-journal","partition":0,"offset":7,"tstype":"create","ts":1637230593993,"headers":["req","3d3beae5-6561-4b42-9731-c7c6c74ce5c7"],"key":"\u0002{\"tenantId\":\"_\",\"contentHash\":\"edc351831a60539d904157020074ef1043868247fb8641e5cf4356407245dd32\",\"contentId\":2}","payload":"\u0002\u0001\u0000\u0000\u0000@e200bb1898f5ccee20f649e98097306fb72a8b32ecf9db64261d13387730dc95\u0000\u0000\u0000�{\n \"type\": \"record\",\n \"name\": \"User2\",\n \"namespace\": \"foo\",\n \"fields\": [\n { \"name\": \"active2\", \"type\": [\"null\", \"boolean\"] }\n ]\n}"}
{"topic":"kafkasql-journal","partition":0,"offset":8,"tstype":"create","ts":1637230594011,"headers":["req","6485fb14-313d-42c2-891b-5b80a6f7b244"],"key":"\b{\"tenantId\":\"_\"}","payload":"\b{\"action\":\"CREATE\"}"}
{"topic":"kafkasql-journal","partition":0,"offset":9,"tstype":"create","ts":1637230594026,"headers":["req","8f807fb9-d581-4976-8750-b3d3d80df333"],"key":"\u0003{\"tenantId\":\"_\",\"artifactId\":\"0b9c15b5-54a5-40d3-9b75-433070d6ad99\",\"uuid\":\"b2c6e59d-b9b7-4be1-84a9-9d0dd907466a\"}","payload":"\u0003{\"action\":\"CREATE\",\"metaData\":{\"name\":\"User2\"},\"globalId\":2,\"artifactType\":\"AVRO\",\"contentHash\":\"edc351831a60539d904157020074ef1043868247fb8641e5cf4356407245dd32\",\"createdBy\":\"\",\"createdOn\":1637230594011}"}
{"topic":"kafkasql-journal","partition":0,"offset":10,"tstype":"create","ts":1637230608757,"headers":["req","6ec25f20-eb62-4914-8e8b-97e9c7fa29c7"],"key":"\t{\"tenantId\":\"_\"}","payload":"\t{\"action\":\"CREATE\"}"}
{"topic":"kafkasql-journal","partition":0,"offset":11,"tstype":"create","ts":1637230608773,"headers":["req","b68d11b9-67fd-427a-a167-e5c438c8334f"],"key":"\u0002{\"tenantId\":\"_\",\"contentHash\":\"b11088caecbc3fcd799b2a289f85502b6c0d00d8113b0fb51789528863e6c0e1\",\"contentId\":3}","payload":"\u0002\u0001\u0000\u0000\u0000@06f0fb80396e5f02a4a5f3d96ba5da6af35ca33ec1251c58698170283d0dd37a\u0000\u0000\u0000�{\n \"type\": \"record\",\n \"name\": \"User3\",\n \"namespace\": \"foo\",\n \"fields\": [\n { \"name\": \"active3\", \"type\": [\"null\", \"boolean\"] }\n ]\n}"}
{"topic":"kafkasql-journal","partition":0,"offset":12,"tstype":"create","ts":1637230608792,"headers":["req","e69c6a1b-7df1-40cd-a640-ac9b3716c687"],"key":"\b{\"tenantId\":\"_\"}","payload":"\b{\"action\":\"CREATE\"}"}
{"topic":"kafkasql-journal","partition":0,"offset":13,"tstype":"create","ts":1637230608807,"headers":["req","6875bbc9-92fe-4572-accc-7dab2bdcd84e"],"key":"\u0003{\"tenantId\":\"_\",\"artifactId\":\"447e73bf-e86b-480b-8e45-3222c0980bc9\",\"uuid\":\"a5fa1ba0-f40a-4591-91c6-a6cb422f2f4a\"}","payload":"\u0003{\"action\":\"CREATE\",\"metaData\":{\"name\":\"User3\"},\"globalId\":3,\"artifactType\":\"AVRO\",\"contentHash\":\"b11088caecbc3fcd799b2a289f85502b6c0d00d8113b0fb51789528863e6c0e1\",\"createdBy\":\"\",\"createdOn\":1637230608791}"}
You can get a Kafka topic dump using Kafkacat directly, however it’s possible to run it via Docker like this:
export PWD=`pwd`
docker run --rm --network=host --volume $PWD:/data edenhill/kafkacat:1.5.0 kafkacat \
-C -b localhost:9092 -t kafkasql-journal -Z -D \\n -e -J
We can now import the sample topic dump into our local Kafka cluster.
However, we were not able to do it using Kafkacat directly, because the data is wrapped
in an envelope with additional metadata.
Therefore, we can use one of the example projects from Apicurio Registry Examples
to create a simple application to preprocess and load the data into the kafkasql-journal topic.
The preprocessing mostly consists of removing the metadata envelope and producing clean messages.
As a note, it is important to use correct encoding, StandardCharsets.US_ASCII instead of UTF when reading the dump file.
Now, we can run the local Registry with the data the user has provided.
First, we build Apicurio Registry with KafkaSQL storage:
mvn clean install -Pprod -Pkafkasql -DskipTests
and then create an environment variable representing the project root:
export PROJECT=`pwd`
To see how the data are being processed and stored, we need to have access to the local database.
By default, it’s an in-memory h2 database, but we’ll use a file-based configuration,
to which we can easily connect from an IDE.
To achieve this, we will override the default value of the quarkus.datasource.jdbc.url property.
Run Apicurio Registry instance with the debugger enabled:
java -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=5005 \
-Dquarkus.http.port=8180 \
-Dquarkus.datasource.jdbc.url="jdbc:h2:file:$PROJECT/registry_database;MV_STORE=FALSE;AUTO_SERVER=TRUE" \
-jar ./storage/kafkasql/target/apicurio-registry-storage-kafkasql-2.1.3-SNAPSHOT-runner.jar | tee log.txt
Now we can connect both the debugger and database client to the application from our IDE.
You can use the following URL, with sa/sa as the username/password options:
echo "jdbc:h2:file:$PROJECT/registry_database;MV_STORE=FALSE;AUTO_SERVER=TRUE"
After loading the data from the Kafka topic into the local database and setting up debugging,
we can inspect the contents of the ARTIFACTS and then the CONTENT tables:
+---------+--------------+-------------------------------------+-----+----------+---------------------------+-------+
|TENANTID |GROUPID |ARTIFACTID |TYPE |CREATEDBY |CREATEDON |LATEST |
+---------+--------------+-------------------------------------+-----+----------+---------------------------+-------+
|_ |__$GROUPID$__ |d0c00bec-3e4a-4386-ad67-b23b5a91ce96 |AVRO | |2021-11-18 11:16:21.817000 |1 |
+---------+--------------+-------------------------------------+-----+----------+---------------------------+-------+
|_ |__$GROUPID$__ |0b9c15b5-54a5-40d3-9b75-433070d6ad99 |AVRO | |2021-11-18 11:16:34.011000 |2 |
+---------+--------------+-------------------------------------+-----+----------+---------------------------+-------+
|_ |__$GROUPID$__ |447e73bf-e86b-480b-8e45-3222c0980bc9 |AVRO | |2021-11-18 11:16:48.791000 |3 |
+---------+--------------+-------------------------------------+-----+----------+---------------------------+-------+
ARTIFACTS table
+---------+----------+----------------+----------------+------------------+
|TENANTID |CONTENTID |CANONICALHASH |CONTENTHASH |CONTENT |
+---------+----------+----------------+----------------+------------------+
|_ |1 |9e15d06c0aa1... |377072c58f39... |{ |
| | | | |"type": "record", |
| | | | |"name": "User1", |
| | | | | ... |
| | | | |} |
+---------+----------+----------------+----------------+------------------+
|_ |2 |e200bb1898f5... |edc351831a60... |{ |
| | | | |"type": "record", |
| | | | |"name": "User2", |
| | | | | ... |
| | | | |} |
+---------+----------+----------------+----------------+------------------+
|_ |3 |06f0fb80396e... |b11088caecbc... |{ |
| | | | |"type": "record", |
| | | | |"name": "User3", |
| | | | | ... |
| | | | |} |
+---------+----------+----------------+-----------------------------------+
CONTENT table
The data has been loaded as expected, and the database content looks good, so we can try to add another artifact:
{
"type": "record",
"name": "User4",
"namespace": "foo",
"fields": [
{ "name": "active4", "type": ["null", "boolean"] }
]
}
Sample Avro schema
and indeed we observe the error we have been attempting to reproduce. The details of the exception are as follows, which corresponds to the reported issue:
Caused by: io.apicurio.registry.storage.impl.sql.jdb.RuntimeSqlException: SQL error: Expected only one result row but got none.
at io.apicurio.registry.storage.impl.sql.jdb.MappedQueryImpl.one(MappedQueryImpl.java:66)
at io.apicurio.registry.storage.impl.kafkasql.sql.KafkaSqlStore.lambda$contentIdFromHash$7(KafkaSqlStore.java:172)
at io.apicurio.registry.storage.impl.sql.HandleFactory.withHandle(HandleFactory.java:44)
at io.apicurio.registry.storage.impl.sql.HandleFactory.withHandleNoException(HandleFactory.java:52)
...
What does it mean? When creating a new artifact, we use multiple messages to perform the necessary operations.
In the case of adding a new artifact, we first make sure that the content of the artifact is stored,
before writing meta-data to the ARTIFACTS table. This ensures that we do not store multiple copies of the same content.
The error tells us, that when we perform the second step, the content we expected is not present in the database,
even though the message responsible for adding it must have been processed before the error occurs.
There may be multiple reasons why this could happen, but after some investigation we noticed a suspicious content of the SEQUENCES
table:
+--------+---------+-----+
|TENANTID|NAME |VALUE|
+--------+---------+-----+
|_ |contentId|2 |
|_ |globalId |2 |
+--------+---------+-----+
The data is wrong, since after we loaded the original data, there were 3 artifacts in the CONTENT table.
This means that the next contentId in the sequence is 3, but content with that ID already exists,
and it belongs to an artifact that has been created earlier.
To find the answer to the corrupted data, we can take a look at the topic dump we have originally used and notice that the messages for some offsets are missing. Furthermore, it seems that those messages are exactly those that cause the sequence numbers to be incremented.
After some investigation, we determined that the missing messages may have been deleted by a feature of Kafka, called Topic Log Compaction. Our hypothesis therefore is, that the messages that should have be kept have been accidentally deleted in this way. To find out more, we will describe how Kafka Topic Log Compaction works.
Kafka Topic Log Compaction
Topic log compaction is a feature in Apache Kafka that allows users to conserve storage space for the topic, by automatically removing old messages in the log. It works by considering a sequence of messages that share the same key, and only keeping the last message in the sequence.
This, however, requires an assumption that any message for the given key contains all state that the application wants to keep. This is not necessarily true for each application, or for all messages, therefore it is important to carefully configure this feature, and disable it if your application depends on keeping every message, even if the key is repeated.
An additional feature is to also remove messages that have a null value, allowing you to delete the whole sequence for the given key
when the topic is compacted. These kinds of messages are called tombstone messages.
In Apicurio Registry, we use tombstone messages when a piece of data, such as an artifact, is deleted.
The reason is that the past operations on that piece of data do not need to be replicated to other nodes,
or preserved after restart.
The most important Kafka properties for configuring log compaction are as follows:
cleanup.policy=compactenables log compaction and activates the following properties.min.cleanable.dirty.ratiothis ratio bounds the maximum space wasted in the log by duplicates, until the log compactor will attempt to clean the log.min.compaction.lag.msthe minimum amount of time that has to pass since a message is written before it can be compacted.delete.retention.msThe amount of time to retain delete tombstone markers. If a consumer starts to read the topic from the beginning, they need to finish reading in this time if it wants to make sure it sees the markers.
If you are using the Strimzi Operator to provision and manage your Kafka cluster on Kubernetes,
you can provide these configuration options on a cluster or topic level (Kafka or KafkaTopic CRD) in the config section:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: kafkasql-journal
labels:
strimzi.io/cluster: my-cluster
namespace: registry-example-kafkasql
spec:
partitions: 2
replicas: 1
config:
cleanup.policy: compact
min.cleanable.dirty.ratio: 0.5
Strimzi Kafka CRD example
Note: If you have not created the topic manually, Apicurio Registry will create the kafkasql-journal automatically.
Make sure you create a CDR for the kafkasql-journal topic, so you can manage it with Strimzi.
Reproducer
Let’s create a procedure to attempt to reproduce the issue and confirm our hypothesis. We are assuming that the Kafka cluster and the Apicurio Registry executable is already prepared by following steps in the previous sections.
- Stop the Registry process.
- Remove
kafkasql-journaltopic, if it exists. -
Create the topic manually with aggressive log compaction settings:
bin/kafka-topics.sh --bootstrap-server localhost:9092 \ --create --topic kafkasql-journal --partitions 1 --replication-factor 1 \ --config min.cleanable.dirty.ratio=0.000001 --config cleanup.policy=compact \ --config segment.ms=100 --config delete.retention.ms=100 -
Create at least 3 AVRO schemas, for example:
{ "type": "record", "name": "User1", "namespace": "foo", "fields": [ { "name": "active1", "type": ["null", "boolean"] } ] }Sample Avro schema
-
Restart the registry, so it will reload messages from the topic into its local database. Remove the database file if you are using the debug settings from earlier.
- Add another AVRO schema to the Registry and observe the error.
Solution
In order to fix the bug, we have to prevent messages, which control the database sequence, from being compacted.
We are already doing this for other types of messages, by making sure that the key value is always unique.
We can do this by including a sufficiently random nonce, such as an UUID, in the message key.
The following is an example ContentId message, that increments a sequence for the CONTENT table, before the fix has been implemented:
{
"topic": "kafkasql-journal",
"partition": 0,
"offset": 1,
"tstype": "create",
"ts": 1638894723320,
"headers": [
"req",
"9dff3fb8-7a1d-41b0-9083-684d9fbfa619"
],
"key": "\t{\"tenantId\":\"_\"}",
"payload": "\t{\"action\":\"CREATE\"}"
}
And the same message after the bugfix:
{
"topic": "kafkasql-journal",
"partition": 0,
"offset": 1,
"tstype": "create",
"ts": 1638894723320,
"headers": [
"req",
"9dff3fb8-7a1d-41b0-9083-684d9fbfa619"
],
"key": "\t{\"tenantId\":\"_\",\"uuid\":\"6875bbc9-92fe-4572-accc-7dab2bdcd84e\"}",
"payload": "\t{\"action\":\"CREATE\"}"
}
Temporary Resolution for Older Apicurio Registry Versions
This issue has already been fixed in Apicurio Registry 2.1.4.Final. If you are not able to upgrade, follow this procedure:
In order to make sure you are not affected by this bug, you need to disable log compaction
for the kafkasql-journal topic in your cluster.
First, check if it is enabled:
bin/kafka-configs.sh --describe --bootstrap-server localhost:9092 --topic kafkasql-journal
If you see cleanup.policy=compact, you are affected. To disable log compaction, you need to switch to the delete
cleanup policy. However, in case of Apicurio Registry, deleting old messages will result in data corruption.
Therefore, you must also prevent messages to be actually deleted, by setting retention.bytes=-1 and retention.ms=-1
(or their server-wide equivalents log.retention.bytes and log.retention.ms). For example:
bin/kafka-configs.sh --alter --bootstrap-server localhost:9092 --topic kafkasql-journal \
--add-config cleanup.policy=delete \
--add-config retention.bytes=-1 \
--add-config retention.ms=-1
If you are using Strimzi, you can apply these settings in the config section of the KafkaTopic or Kafka CRD:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: kafkasql-journal
labels:
strimzi.io/cluster: my-cluster
namespace: registry-example-kafkasql
spec:
partitions: 2
replicas: 1
config:
cleanup.policy: delete
retention.bytes: -1
retention.ms: -1
Strimzi KafkaTopic CRD example
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
namespace: registry-example-kafkasql
spec:
kafka:
config:
# ...
log.cleanup.policy: delete
log.retention.bytes: -1
log.retention.ms: -1
version: 2.7.0
# ...
Strimzi Kafka CRD example
However, this configuration change does not fix the existing corrupted data in the database. Luckily, we can use the export-import feature of the Apicurio Registry to force a reset of the database sequences, so the error no longer occurs. This will keep your existing data intact.
To perform this reset, create an export file from an empty Apicurio Registry, using the following example command:
curl localhost:8180/apis/registry/v2/admin/export --output export.zip
and import it into the Apicurio Registry instance you want to fix:
export PWD=`pwd`
curl -X POST -H 'content-type: application/zip' --data-binary "@$PWD/export.zip" localhost:8180/apis/registry/v2/admin/import
Note: If you do not want to provide your own export file, you can use this example one,
generated from an empty Apicurio Registry instance, version 2.1.3.Final.
Thank you for using and supporting Apicurio projects! As always, if you have any suggestions or encounter any problem, feel free to contact the team by filing an issue in GitHub